

Intro to assisted fertility
Any successful pregnancy is viable with just one egg. As an increasing number of women delay pregnancy until their 30s and 40s, getting pregnant is increasingly a sociotechnical process. Assisted reproductive technologies can force women’s ovaries to produce a clutch of eggs at once…but it cannot force women to produce high quality, viable eggs. Quality still depends on age, with a higher rate of chromosomal abnormalities present in any given egg, the older mom is. The question becomes: what quantity of mixed quality eggs is enough to get to a live birth? Is the likelihood of getting a live birth correlated with the number of eggs retrieved? Yes. But how many eggs does it take?
As with almost all fertility issues, that question rests on the age of the egg. Usually, the age of the egg is the same as the age of the mom-to-be. Now that eggs can be frozen (in time and in the freezer), the age of the egg can be younger than the age of the mom-to-be.
A study by Sunkara, Rittenberg, Raine-Fenning et al. looked at data from 400,135 IVF cycles performed in the UK from 1991 to 2008. They found that 15 eggs is basically the magic number. No matter her age, a woman’s chance of getting a live birth increases up to ~15 eggs. Less than that OR more than 20, her chances for live birth are lower. Notably, most women did not make 15 eggs: “The median number of eggs retrieved was 9 [inter-quartile range (IQR) 6–13] and the median number of embryos created was 5 (IQR 3–8).”
For those freezing eggs, it is especially productive to wonder how the number of frozen eggs impacts the chance of a live birth because egg freezers could opt for more than one cycle (if they can afford it). The study I am quoting does NOT look at egg freezers, it only looks at IVF patients. There are not enough egg freezers who have gone on to try to become moms to produce data nearly this robust. Biologically, the stimulation protocol for egg freezers and IVF patients is largely the same so the number of eggs harvested should be decently reliable across populations. Egg freezers may produce more eggs than IVF patients, because egg freezers aren’t reporting infertility. On the other hand, IVF patients in this study were infertile for a number of reasons, the largest percentage had male-factor infertility. Pregnancy rates may vary between IVF and egg freezing patients. IVF patients usually get pregnant using fresh embryos. If they do freeze material before implantation, they usually freeze embryos which survive the thawing process better than a single egg does.
What Works
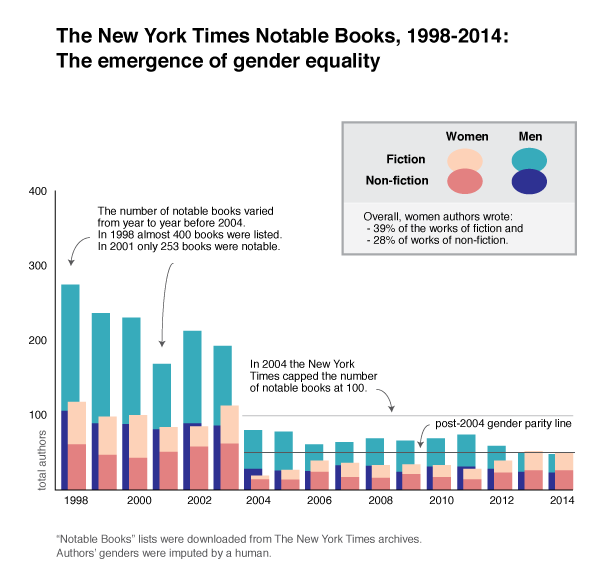
The nomogram above is able to display chances of live birth by age group using a U-turn in the trend line for each age cohort. This demonstrates that the chance of live birth rises until 15 and then drops for egg counts higher than ~20 no matter how old the woman.
This graphic has a number of key characteristics. First, it is legible in black and white, which is key for printing in academic journals. Academic journals rarely print in color. Second, the nomogram allows each age cohort to be visualized without overlap. If this were presented with a million lines – one for each age cohort – there would be overlap or bunching and it would be harder to understand each age cohort clearly. Third, the U-turn shape allows us to see that there is an optimal number of eggs, above and below which sub-optimal outcomes arise. Fourth, the authors do not try to hide the fact that these types of assisted fertility are low probability events. The maximum probability of a live birth is just over 40% for the youngest cohort of women who produce the optimal number of eggs for retrieval.
Overall, the two key strengths of the nomograph type are that it is able to show each age cohort without overlap and that it allows for the data to U-turn in cases where there is an inflection point.
What needs work
Many of us are accustomed to comparing slopes in trend lines. This format does not allow for any kind of slope, making it difficult to visualize the shape of the trend. From looking at other plots, live-by-birth by eggs retrieved appears to be a Poisson distribution. In other words, it is a lot better to have, say, 8 eggs retrieved than 7, but only a little bit better to have 15 eggs retrieved than 14 because the slope rises faster for smaller numbers. The nomogram *does* visualize this. Look at all the space between 1 and 2 eggs retrieved and the small amount of space between 14 and 15 eggs retrieved. I happen to think it is easier to understand the changes in relative marginal impact with slopes than distances. That could simply be because I am more used to seeing histograms and line charts than nomograms, but I see no reason to pretend that visual habits don’t matter. Because people are used to making inferences based on slopes, using slopes to visualize data makes sense.
What does this mean for fertility
Women who are undergoing IVF – meaning that they are aiming to end up with a baby ASAP – cannot do much more than what they are already doing to increase their egg count. Women who are planning to freeze their eggs for later use may be able to use this information to determine how many cycles of stimulation they undergo. One cycle may not be enough, especially if they are expecting to have more than one child. Eggs from two or more stimulation cycles can be added up to get to the 15-20 egg sweet spot per live birth.
Of course, egg freezing is still an elective procedure not covered by insurance. The cost is likely to prohibit many women from pursuing even one round of egg freezing, let alone multiple rounds.
References
Sesh Kamal Sunkara, Vivian Rittenberg, Nick Raine-Fenning, Siladitya Bhattacharya, Javier Zamora, Arri Coomarasamy; Association between the number of eggs and live birth in IVF treatment: an analysis of 400 135 treatment cycles. Hum Reprod 2011; 26 (7): 1768-1774. doi: 10.1093/humrep/der106
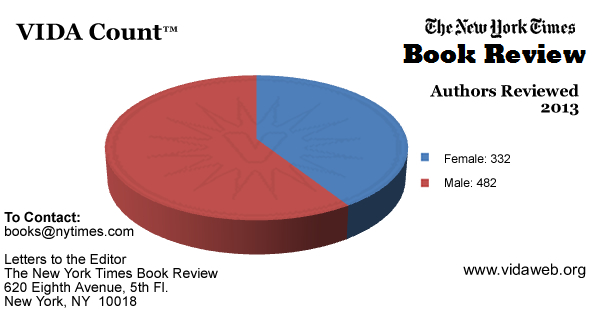








{kind=link}
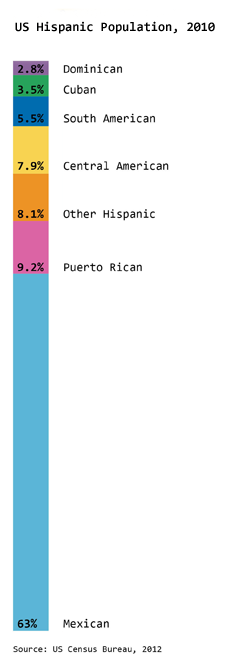
{kind=link}
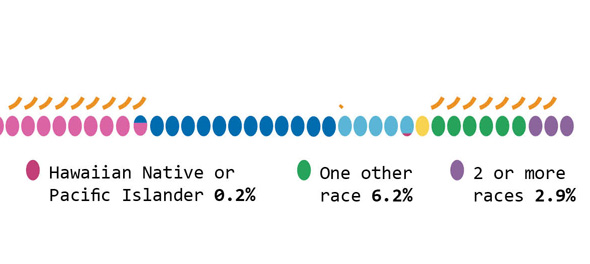
{kind=link}
{kind=link}