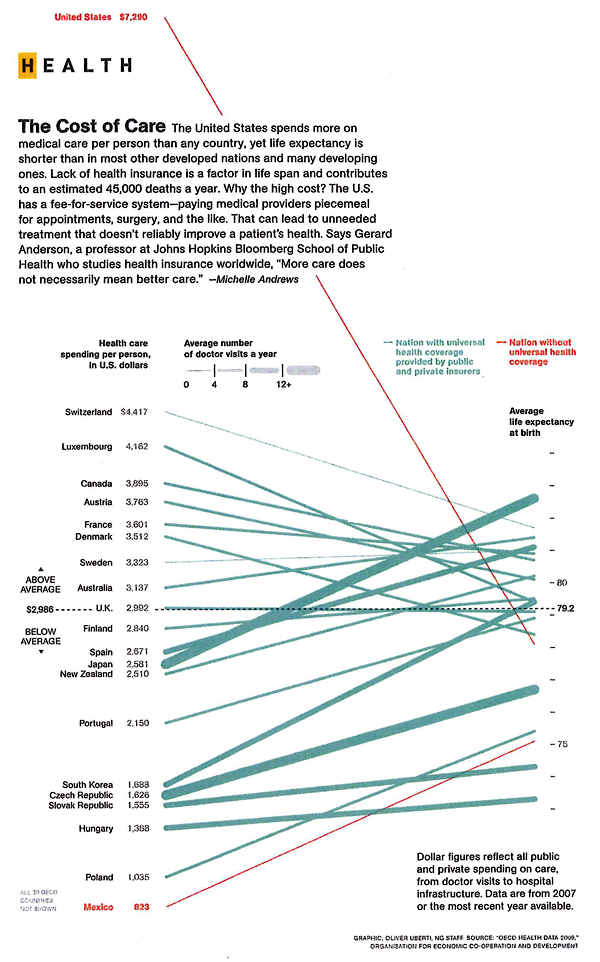
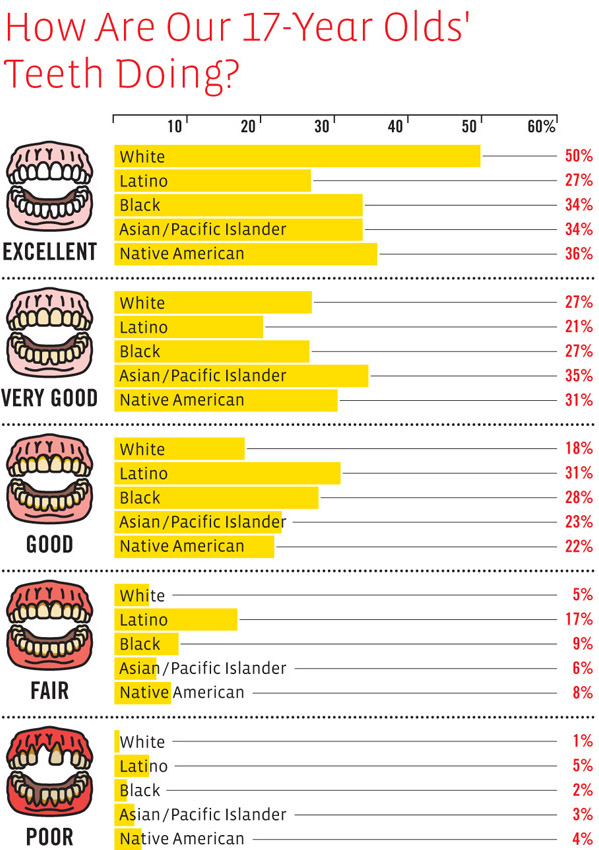
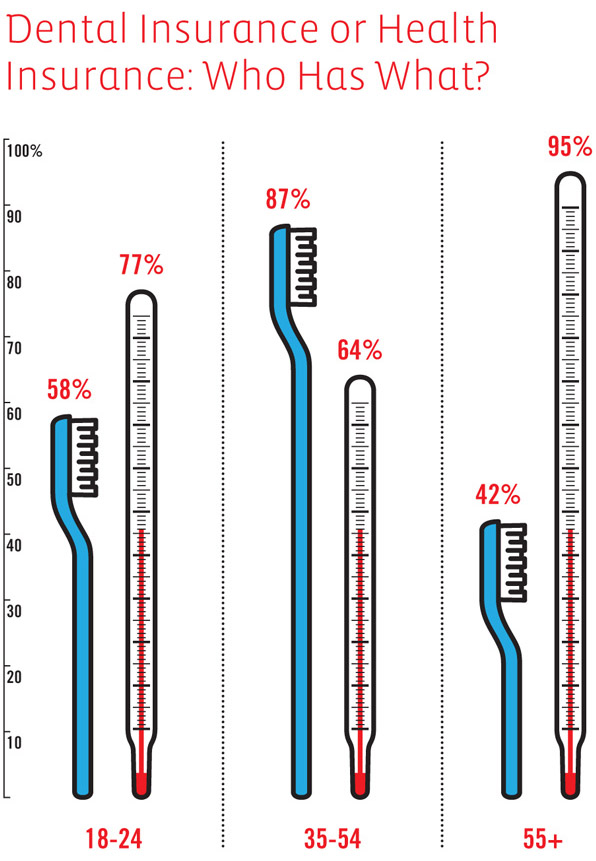
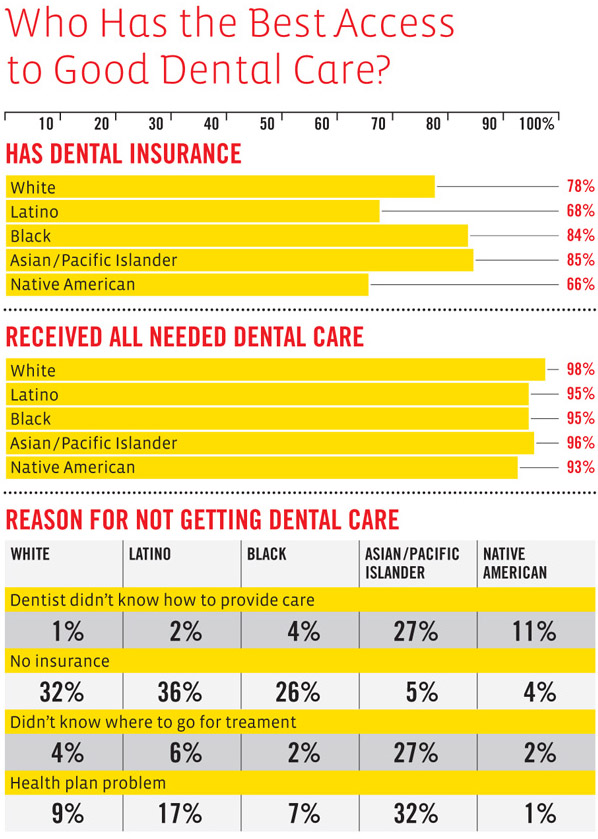
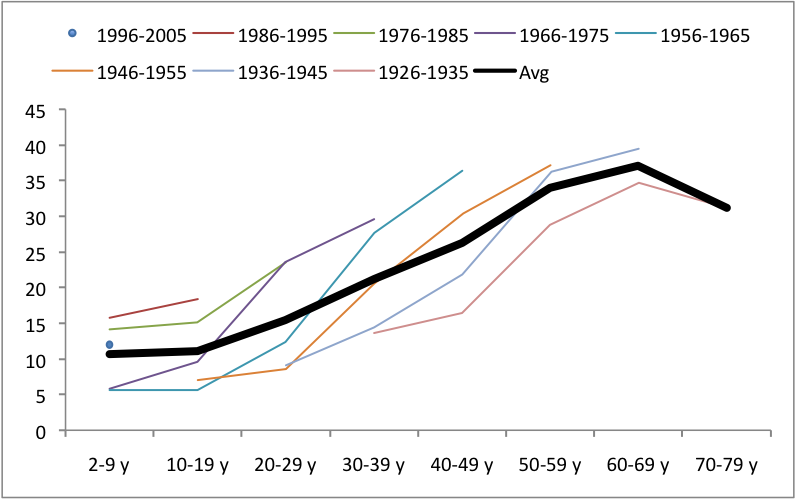
![Visualizing How A Population Grows To 7 Billion | NPR [Click for video]](https://thesocietypages.org/graphicsociology/files/2011/10/NPR-world-population-growth-still-01.jpg)
What works
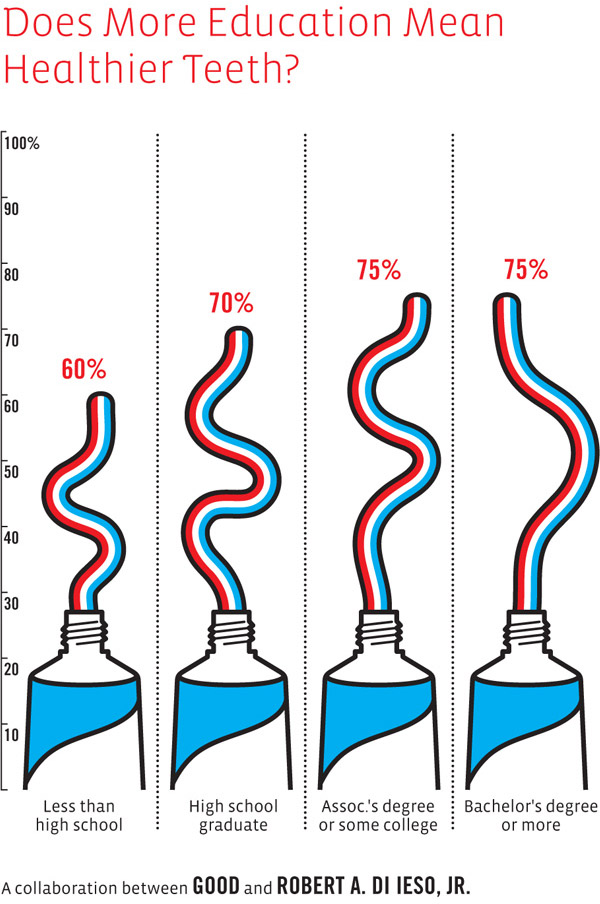
This video does an excellent job of explaining how population growth has happened with beautiful visualizations. Click through to watch it. It’s worth it.
![Visualizing How A Population Grows To 7 Billion | NPR [Click for video]](https://thesocietypages.org/graphicsociology/files/2011/10/NPR-world-population-growth-still-02.jpg)
What comes next
It would be nice to have a visualization that could combine population growth visualizations with quality of life visualizations. Quality of life was pretty dismal in the beginning – infant mortality was high, maternal death was high, life times were short and much more of them were spent in grueling conditions. The rising tide of domestic agricultural practices raised all boats. But then quality of life started to become stratified – some people in some places had it pretty good while others were still facing not such great conditions. Now quality of life is extremely stratified but starting to diminish globally and will continue to diminish as the impacts of climate change set in (not to mention the non-climate related concerns associated with what happens when the planet starts to reach its limit in terms of how many human lives it can support at high levels of ‘quality of life’). Fewer people will be able to eat meat regularly (which may or may not be considered an indicator of high quality of life), more people will get asthma as we all move to cities congested with the exhaust of internal combustion engines and coal-fueled power plants, more people will live in drought stricken places, and more people will end up in conditions of poverty if rates of inequality continue as they are.
The video is beautiful as it is. But the beautiful polish helps obscure the notion that population growth is not necessarily a good thing.
References
Cole, Adam and Starbard, Maggie. (31 October 2011) Visualizing how a population grows to 7 billion. NPR.org.