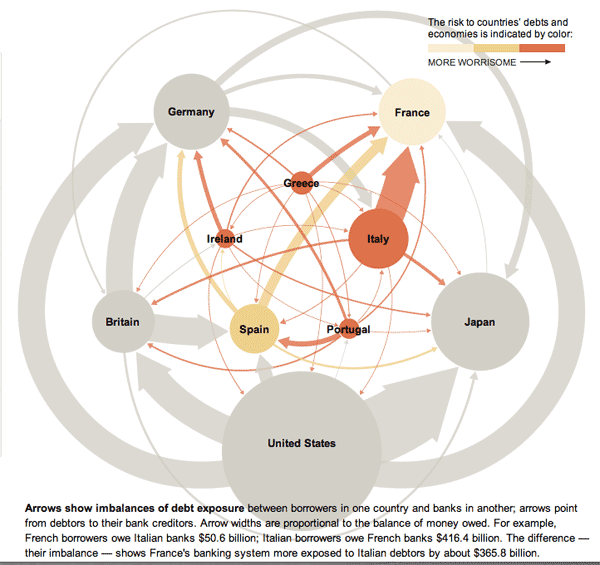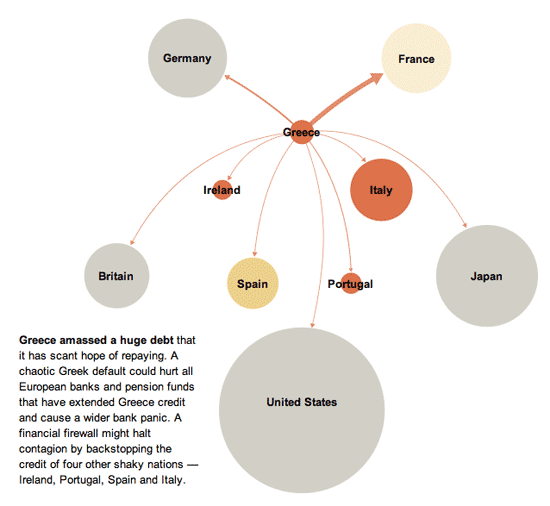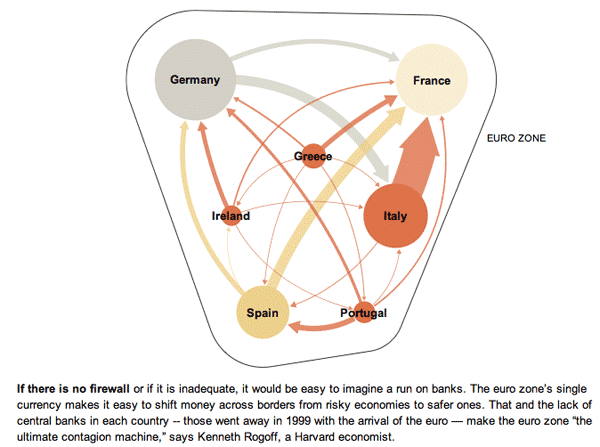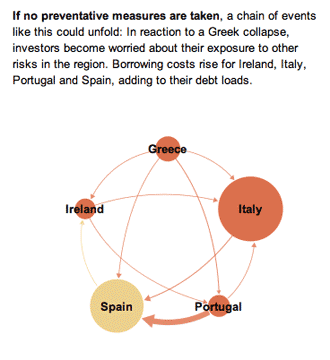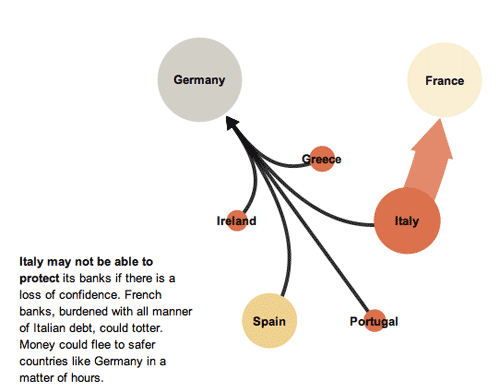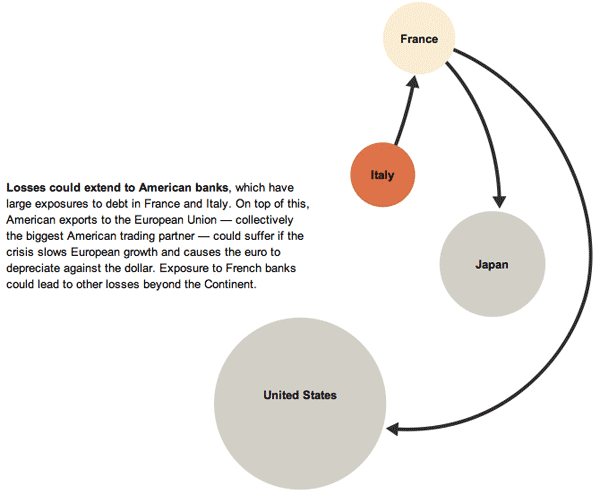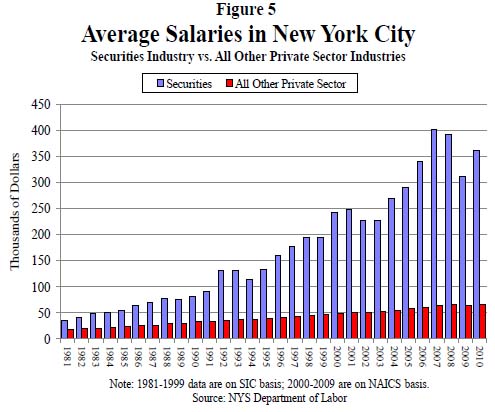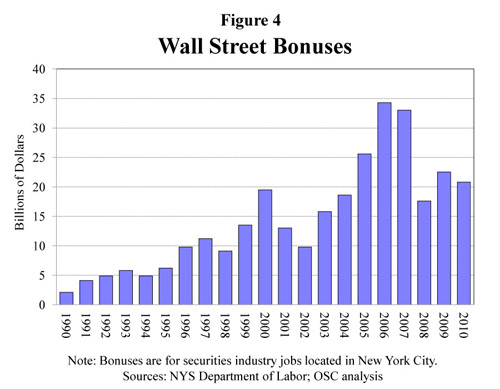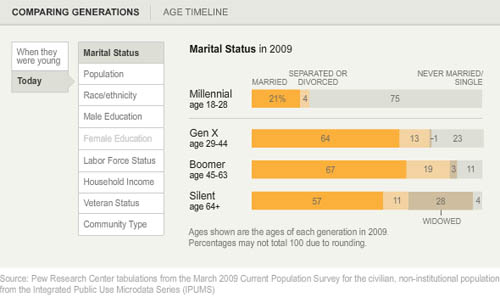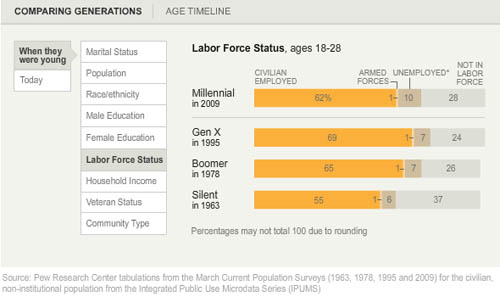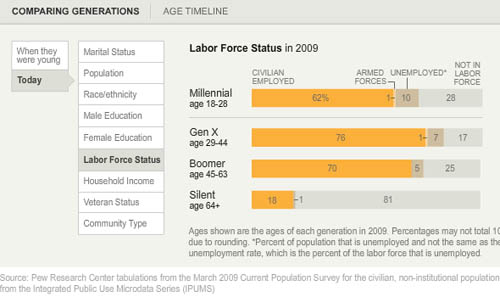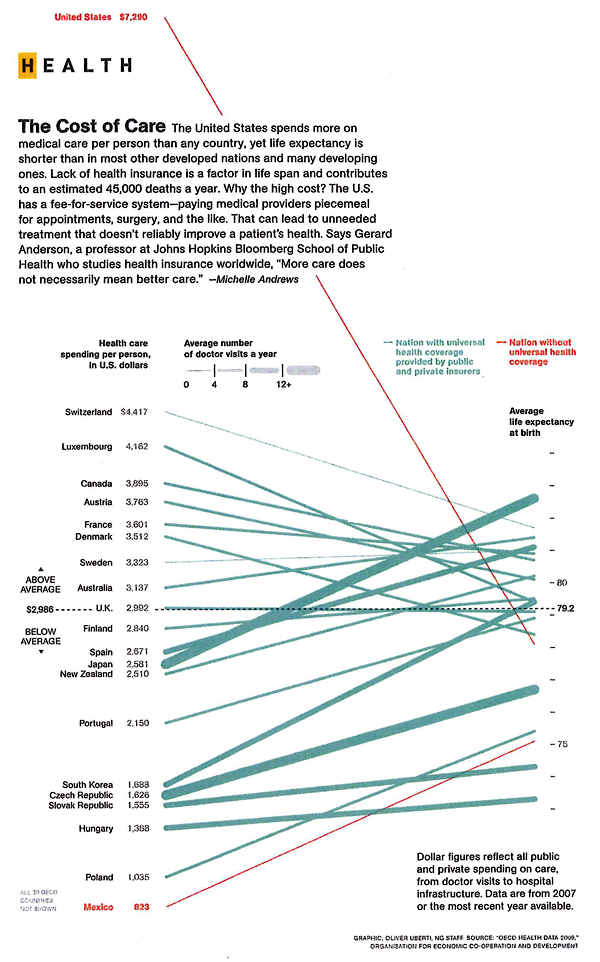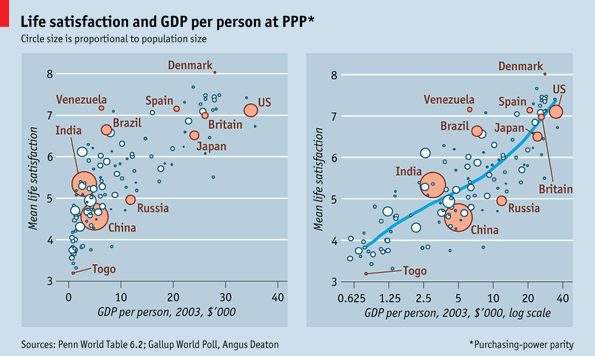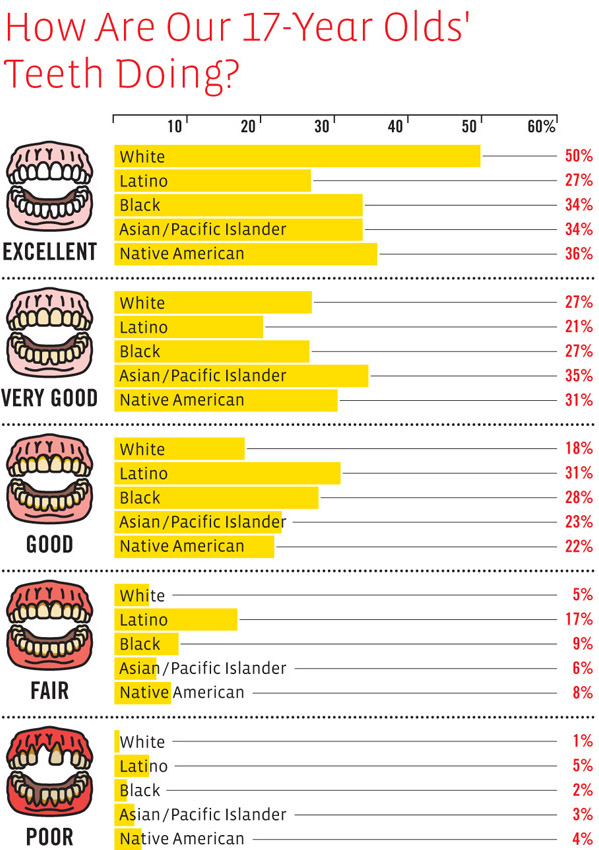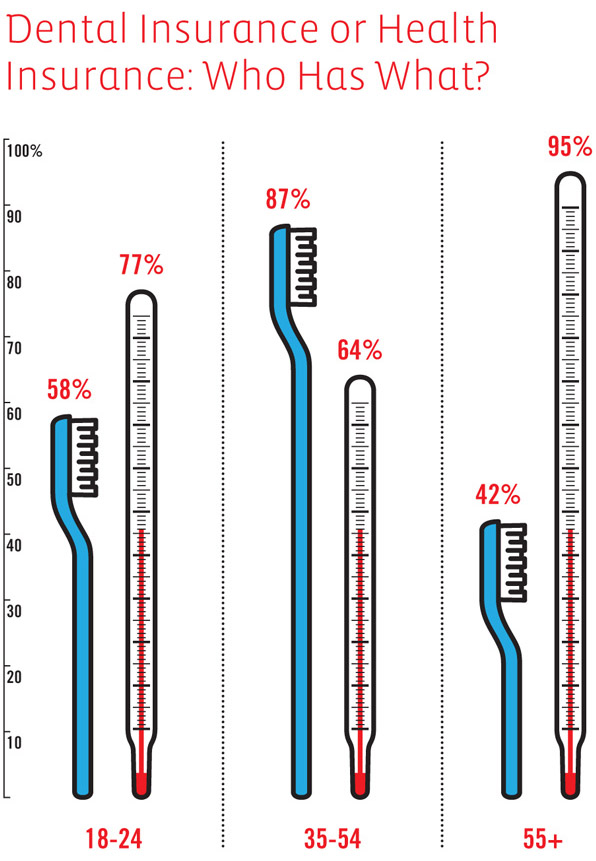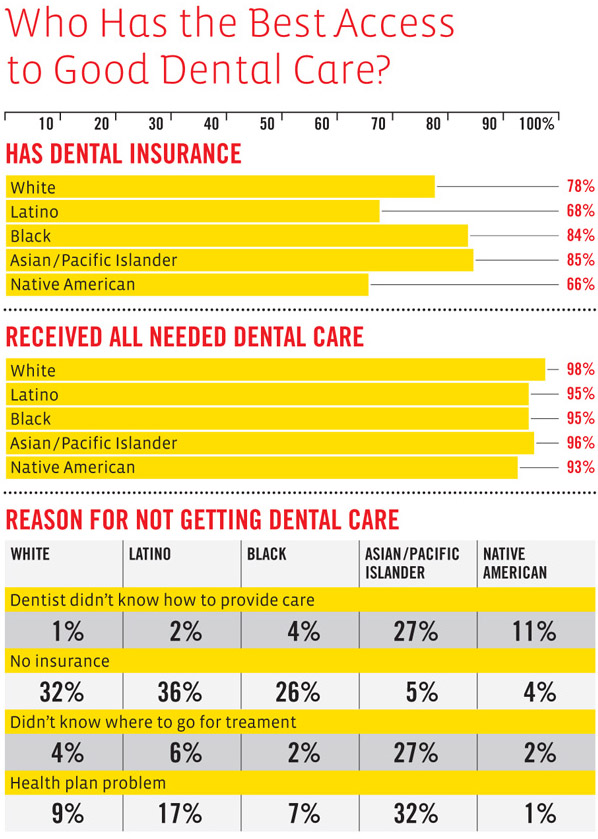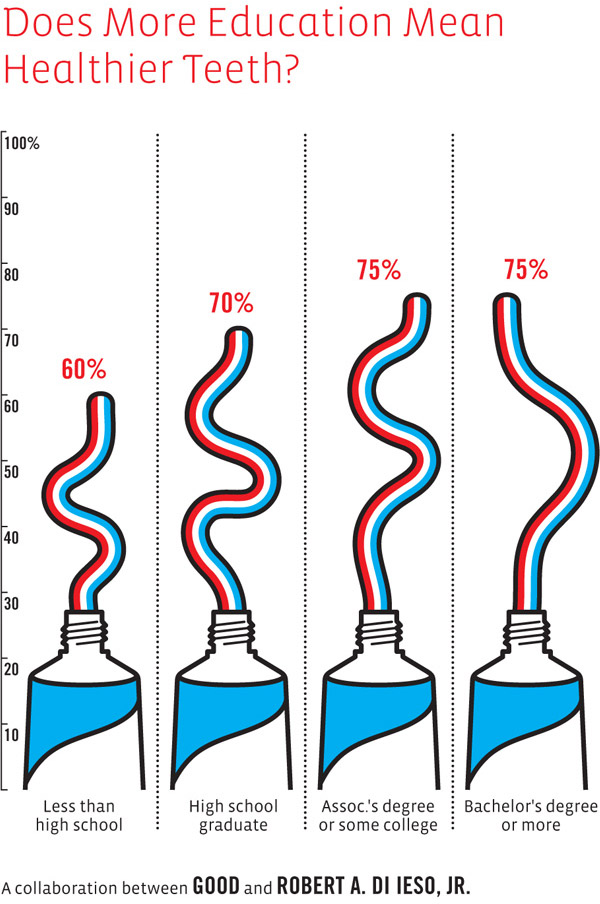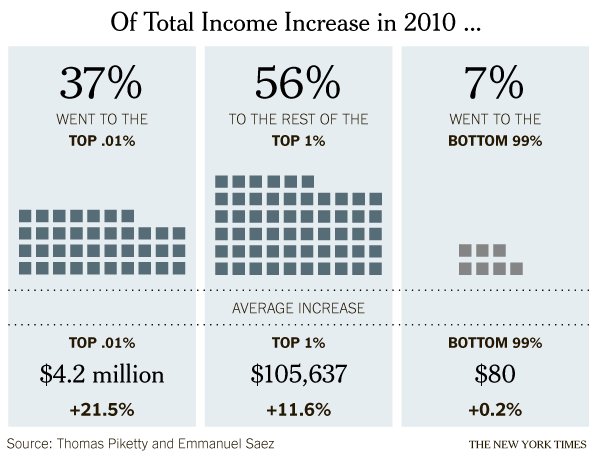
What works
Quoting Justin Wolfers who I happen to follow on twitter, it’s generally not good practice to look at a single year’s worth of data, especially when it would be easy to get comparable data going back for years. Still, in this particular economic news climate, many of the people who are likely to see this graphic have some sense of the relevant contextual data in their heads already, thanks in part to the Occupy Wall Street movement but also to the often thankless work of social scientists and labor statisticians who have been working on issues like income distribution since long before OWS congealed. That’s a long-winded preamble to summarize two fairy simple achievements in this graphic:
- This graphic demonstrates that it is possible to make it appear as though there was income growth for everyone in 2010 – even that bottom 99% saw an INCREASE in income, albeit a tiny one – despite the fact that the economy was rather slack in 2010.*
- The graphic amply demonstrates that the post-2008 world is quite similar to the pre-2008 world in the sense that income distribution is dramatically skewed. The rich do get richer.
One thing that the article draws readers’ attention to is that the study, which looked at tax returns, and the graphic are about income. Thus, we are not talking about the distribution of wealth (ie the accumulated capital that results from single year uneven distributions of income and a lack of attendant unequal distributions of spending). The rich folks in 2010 got most of this income from labor, not from returns to investments.
What needs work
*One thing I fear is that this graphic obscures an important truth by comparing only the top 1% to the bottom 99%: many people had declining income in 2010. This graphic makes it seem like everyone got *something* but really, the folks at the bottom of this distribution got no increase or a decrease, for the most part. From a statistical leverage point of view, the 99% is just too big of a group to be all that revealing. The spotlight is on the 1% in both this graphic and the current political economic discourse in a way that curiously contributes to the inaccurate notion that America is a classless society. One of the things that makes the 1% vs. the 99% a clever rhetorical frame in America is that we all thought we were in the middle class before OWS and we can now continue to think of ourselves as one giant middle class with this troublesome small pimple of a distribution problem to sort through represented by a mere 1%. The whole 99% sounds so comfortably inclusive and that pesky 1% must, in the end, be a manageable problem because it sounds kind of small-ish. It’s only 1%.
Of course, the rhetorical move of splitting the American population into the 1% and the 99% sets up for all these fantastic (as in remarkable, not as in laudable) statements, like the one made by the graphic, that go something like: “The top 1% of the population got 93% of the income in 2011 while the bottom 99% only got 7%.” Being able to make comparisons like that is a more straightforward, empirically sound reason for the 99% vs. the 1% framing than one that seems to make an effort to avoid noting that America has a lower class.
Relative frame: US vs the world
If you are not in the 1% – and most of you are not – I imagine you might be feeling righteously indignant right now. But think of it this way. All of you have computers and internet connections, most of you are American or English according to the google analytics for this blog, and are therefore in the global 1%. It’s a golden rule problem not in the sense that you should do unto your less fortunate global neighbors what you would have your more fortunate doctors/bankers/lawyers/businesspeople do unto you – though I suppose that might apply, too – but more along the lines of, ‘those who have the gold, rule’. Revisit C. Wright Mills The Power Elite, skim a bit of Marx, and maybe look at something a little more recent like Tim Mitchell’s Rule of Experts and this graphic and the entire OWS narrative is analytically similar to a snapshot of a sports event: different in its particulars but so predictable it’s almost trite. It would be trite if there weren’t so much at stake.
References
Rattner, Stephen. (25 March 2012) The Rich Get Even Richer. In the New York Times, The Opinion Pages.
Note: The author, Mr. Rattner, is himself a member of the 1%. Sometimes when I see graphics like this, I wonder if people who know that they are in the 1% are secretly congratulating themselves for having done so well compared to the rest of us.