What works
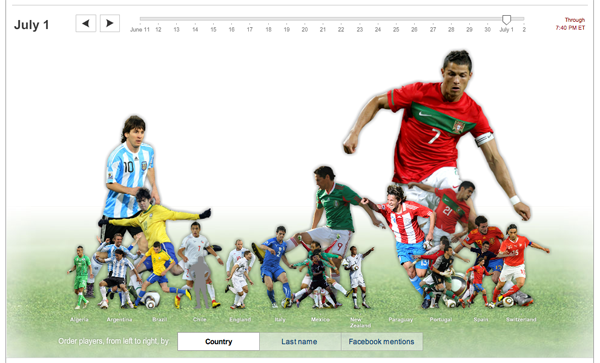
This is really fun to play with and technically sophisticated. Move the slider around the the image of the players grow and shrink relative to their mentions on facebook that day. Hold the mouse over a player and it will tell you their name, what country they play for, and the percentage of facebook wall posts in which they were mentioned that day.
Try it. You’ll like it.
What needs work
Of course, I lament the fact that so much time and effort is devoted to sport when it could be devoted to making similarly complex graphics about social science topics. On the other hand, I am somewhat glad that social scientists aren’t using facebook wall posts as evidence. Sure, they are useful within the realm of facebook, but even this example amply demonstrates that facebook is not holding a mirror up to the “real world”. (I believe facebook to be part of the real world, not a mirror of the real world. As such, it cannot be taken to contain some kind of 1:1 relationship with the rest of our experience, if only we can use bigger processors and more sophisticated techniques to analyze the steady flow of new data.)
I wonder how the mentions of individual players matches up with viewership information. While we’re wondering about that, I’d also add the wonder that the World Cup has inspired collective watching like nothing I can think of besides the Super Bowl and the World Series. Bars in Manhattan can barely contain all the people who want to watch. And people are watching on their computers (thanks univision!) at work. How does Nielsen deal with that? Will we ever have more or less accurate information about how many people watched the 2010 World Cup? Besides advertisers, does anyone care about how many of us watched this? (Personally, I’m curious to see the demographic breakdown of who watched – seems to skew quite young as far as sporting events go.)
Important note
Viva España!
But I won’t be posting to facebook about their match tomorrow because I’ll be too busy watching it. And then celebrating their win.
Reference
SHAN CARTER, BEN KOSKI and KEVIN QUEALY. (2 July 2010) Top World Cup Players on Facebook, Day by Day. New York Times interactive graphic.