Cyborgology readers, I need your help. I’ve put the post I was writing for today on hold because I’m short a key piece of terminology, and I’m hoping one of you can either a) point me to a good preexisting term, or b) help me to assemble a term that’s a bit more graceful than the ones I can come up with on my own.
The phenomenon I’m trying to describe is one that I’ve encountered a number of times over the past week, and is a theme I identify fairly often in conversations about newer technologies. I describe it below, first generally and then with a couple recent examples.
To set up my description, remember that ‘the physical’ and ‘the digital’ aren’t separate worlds, and that human behavior ‘online’ has a whole lot in common with human behavior ‘offline.’ Note that I’m specifically avoiding saying that behavior online “mirrors” behavior offline here, because that would imply that online and offline expressions of a given behavior are actually two separate behaviors that closely resemble each other; after all, your reflection closely resembles you, but you and your reflection are not the same thing. I’m starting from the assumption that the various online and offline expressions of a behavior (sharing, bullying, etc) are, at the most fundamental level, the same behavior.
Now that we’ve established that, here’s what I’ve observed: a new technology (or a change to an existing technology) enters the scene, and makes more explicitly visible to us some facet or aspect of human social behavior that a) is usually more latent, subtle, or obscured, and that b) makes us feel anxious, uncomfortable, or even repulsed. The behavioral facet we see on display through the new technology isn’t new, it’s just newly visible (or more visible than it was before); it is also not unique to behavior connected to the new technology, even if the affordances of that technology seem to encourage the specific behavior.
When we try to identify and explain our unpleasant feelings, however, sometimes we don’t correctly identify the source of our discomfort as having been forced to confront a distasteful aspect of how our society works that we would rather have kept ignoring. Instead, we blame the new technology—and we blame it not for being a too-effective lens, but rather for “causing” or even “being” the unpleasant aspect of our society itself.
To help illustrate what I’m talking about, here’s a couple recent examples:
1) Klout. We love to hate Klout—or at least, I love to hate Klout; as I’m so fond of repeating, Klout “encourage[s] nothing good”—but let’s face it: “social ranking” doesn’t happen only through Klout. Social ranking existed well before Klout (else, why would anyone have bothered to built Klout? The concept would have made no sense), and it had the power to affect who got jobs and preferential treatment before Klout, too. At the most basic level, Klout isn’t creating any new kinds of human behavior; Klout is just making more explicit and blatantly visible something that’s usually easier to hide or ignore. Does that something (social ranking) make us uncomfortable? Yes it does. And is Klout trying to smack a glossy veneer of Science™ onto social ranking? Yes it is (and that’s what really gets me). But in the end, what we’re doing when we hate Klout is resenting it for forcing us to acknowledge something about our society we’d rather ignore. Pretending that Klout is the cause rather than a symptom is just an attempt to re-obscure what’s too disquieting to have in direct view.
2) Facebook’s recent announcement that it will give users the option of paying to promote their posts on the site, so that more of their ‘friends’ see them. There’s a lot tied up in here to dislike (where’s that “dislike” button when you need it?): the idea that money talks, the idea that we have to buy our friends’ attention (we don’t like to think about friendship and money at the same time), the idea that our care and attention—two important aspects of friendship itself—can be purchased, the idea that people should act like corporations (first corporations get to be people, now this?), and the idea that your personal identity has become a brand identity, to name just a few. But again, promoted status updates are a symptom, not the cause; Facebook wouldn’t be rolling out this option if it didn’t think people would actually use it. We can defriend people who promote status updates all we want, but again, this is just an effort to re-obscure; the problem (problems, really) isn’t the promoted updates themselves.
There are other recent examples related to self-tracking and decision-making apps that I’ll be talking about next week, but for now, I’m looking for some new words:
OH GOD CAN’T LOOK
What do we call what it is that we’re really reacting to when we lash out against technologies like Klout and promoted status updates, which is the fact that something threatening, distasteful, and inescapable is now too visible, too explicit, too overt, too blatant for comfort, is displayed in too-stark relief, has been distilled down to a too-bitter concentrate that’s near impossible to swallow? “Explicitization,” “salientization,” and “deobscuration” start to get at the point, but I have to admit: they’re pretty awful as words.
Similarly, what do we call our reactions, our misplaced resentment? What do we call the attempt to re-obscure that which we don’t want to confront by trying to turn the occasion for visibility into the phenomenon itself, by treating the setting of a behavior’s display as its root cause?
Please leave your ideas and suggestions in the comments section; I’m looking forward to your responses!
As if we needed more examples to demonstrate that ‘the digital’ & ‘the physical’ are part of the same larger world, it seems there’s no end to the applicability of demographic metaphors to trends in social media. I wrote about App.net and “white flight” from Facebook and Twitter last month, so you can imagine how my head broke on Monday when I first heard about “New MySpace.” My first question—after, “wait, what?”—was, “Is this like when the white people start moving back into urban cores to live in pricey loft conversions?”
I didn’t do a detailed overview of danah boyd’s (@zephoria) work on MySpace, Facebook, and white flight last time, so I start with that below (though I recommend that anyone interested in this topic check out boyd’s very readable chapter in Race After the Internet, which you can download here [pdf]). I then look at some of the coverage of New MySpace this week to make the argument that there are some strong parallels between the site’s impending “makeover” and the “urban renewal” efforts sometimes called gentrification or regentrification.
Wait, which one’s ours again?
Myspace, Facebook, and White Flight
In a nutshell, boyd’s argument is this: 1) though the migration of many young people from MySpace to Facebook that began around 2006 was not explicitly about race or class, race and class factors both strongly shaped those shifts; 2) the ways social media users and journalists alike talked about MySpace and Facebook during that time mirrored the ways people talked about the city and the suburbs during white flight; 3) drawing the parallel between white flight and social media white flight illustrates that social divisions are reproduced in online interaction, and are not in fact magically erased by the Internet’s technoutopian magic dust (my term).
Boyd describes how, over the 2006-2007 school year, the young people she was studying began to self-sort across MySpace and Facebook. 2006 was when Facebook first became available to high school students; it’s also important to remember that MySpace (which began based around music and nightlife culture) was getting further onto parents’ bad side through media hype about sexual predators, whereas Facebook (which was at first offered only to students at the most elite universities) was associated with the middle-class ideal of attending a four year college. Slowly, a pattern began to emerge: white and Asian students, more affluent students, and more ‘mainstream’ students were more likely to join or migrate to Facebook, while black and Latina/o students, less affluent students, and more ‘subcultural’ students were likely to join or keep using MySpace:
What distinguishes adoption of MySpace and Facebook among American teens is not cleanly about race or class, although both are implicated in the story at every level. The division can be seen through the lens of taste and aesthetics, two value-laden elements that are deeply entwined with race and class. It can also be seen through the network structures of teen friendship, which are also directly connected to race and class. And it can be seen through the language that teens – and adults – use to describe these sites, language like Kat’s that rely on racial tropes to distinguish the sites and their users. The notion that MySpace may be understood as a digital ghetto introduces an analytic opportunity to explore the divisions between MySpace and Facebook – and namely, the movement of some teens from MySpace to Facebook – in light of the historic urban tragedy produced by white flight. Drawing parallels between these two events sheds light on how people’s engagement with technology reveals social divisions and the persistence of racism.
Boyd observes that the language people used to describe MySpace and Facebook (as well as MySpace and Facebook users) closely mirrors the language people use to talk about ‘the inner city’ and the suburbs. Facebook was safe and protected; MySpace was dangerous and full of predators. Facebook’s stark one-size-fits-all layout (the digital equivalent of suburban tract houses) was “clean,” while infinitely customizable MySpace profiles were “ghetto” and covered in “bling”—and, later, the digital graffiti that spammers leave on abandoned profile pages. As boyd points out, “while style preference is not inherently about race and class, the specific styles referenced have racial overtones and socio-economic implications. In essence, although teens are talking about style, they are functionally navigating race and class.”
Not everyone appreciated that MySpace profiles could be customized.
Facebook users were also more likely to denigrate MySpace and MySpace users. Not everyone on MySpace liked Facebook’s un-customizable layout, but Facebook users “argued that the styles produced by MySpace users were universally ugly” (emphasis mine). Facebook users described themselves as “cultured,” but described MySpace users as “lower class” and “more likely to be barely educated and obnoxious.” By 2009, ‘everyone’ was supposedly on Facebook, while ‘no one’ was still on MySpace—even though the sites still had about the same number of visitors. It’s not that no one was still on MySpace; it’s that, thanks to the strong pull of network effects, people who were not on MySpace themselves were far less likely to know people who were on MySpace. In boyd’s words, “The network segmentation implied by a ‘digital white flight’ also helps explain why, two years later, news media behaved as though MySpace was dead. Quite simply, white middle-class journalists didn’t know anyone who still used MySpace.”
Boyd admits that the white flight metaphor is not a perfect fit for the racialized migration of some users from MySpace to Facebook, and acknowledges as well that
Given the formalized racism and institutionalized restrictions involved in urban white flight, labeling teen movement from MySpace to Facebook as “digital white flight” may appear to be a problematic overstatement. My goal is not to dismiss or devalue the historic tragedy that white racism brought to many cities, but to offer a stark framework for seeing the reproduction of social divisions in a society still shaped by racism.
And there is a lot to be gained by looking at these shifts in usage through the lens of white flight. I want to highlight in particular the point that individual actions and choices are not race- or class-neutral just because individuals do not believe or feel themselves to be race- or class-motivated. As boyd explains,
To the degree that some viewed MySpace as a digital ghetto or as being home to the cultural practices that are labeled as ghetto, the same fear and racism that underpinned much of white flight in urban settings is also present in the perception of MySpace. The fact that many teens who left MySpace for Facebook explained their departure as being about features, aesthetics, or friendship networks does not disconnect their departure from issues of race and class. Rather, their attitude towards specific aesthetic markers and features is shaped by their experiences with race and class (emphasis mine).
In other words, before you’re tempted to cry out in indignation, “But I’m not racist,” remember that you don’t have to be thinking overtly racist (or classist) thoughts for your actions to have racialized or class-related implications and effects. Okay? Okay.
Translated: “Don’t worry, it’s only gentrification”
(Re)gentrification
Since many definitions of “regentrification” redirect to “gentrification,” I need to take a second here to clarify some terminology. I’ve gone on about the definition of ‘gentrification’ before, but the here’s the nutshell recap. Technically speaking, “to gentrify” is a transitive verb; it is something someone does to something or someone else, namely “renovate and improve… so that it conforms to middle-class taste,” or, in the case of a person or lifestyle, “make… more refined or dignified.” By denotation ‘gentrification’ is a class-based phenomenon only, but when people use the word ‘gentrification’ to talk about something going on in a neighborhood, they more often than not mean that more white middle-class people are moving into that area. By connotation then, ‘gentrification’ takes on both race- and class-based meanings. I think this is intensely problematic, but I don’t have a good way around it at the moment (and would appreciate suggestions!).
“Regentrification,” on the other hand, doesn’t seem to have a dictionary meaning of its own, but I’ve observed that—like ‘gentrification’—‘regentrificaton’ has strong racial connotations; it seems almost always to be used to mark an influx of white middle-class people specifically. ‘Regentrification’, however, seems to have more strongly polarized connotations. For sociologists and long-time neighborhood residents, for instance, ‘regentrification’ tends to be a critical term, as when a former Georgia State Representative says, “Regentrification, that’s just a nice word for taking black folks’ property.”
For the purpose of this post, I’m going to use the term (re)gentrification to order to reference the combination of ‘gentrification’ and ‘regentrification’, and to signal three things.
The first is that (re)gentrification is part of the legacy of white flight, something embraced by those middle-class whites who reject suburban livingbecause they seek something more “authentic” than tract houses, because they’re ‘nostalgic’ for older architecture from a different time, because they’re “settling down” later and want to be closer to nightlife longer, or because they just hate that long suburban commute.
The second is that (re)gentrification can have negative effects (including, but not limited to, the displacement of current residents), and may not be welcomed by the people who lived in an area before (re)gentrification began.
The third is that (re)gentrification, when cast as a good thing, tends to treat ‘the neighborhood’ or ‘the area’ as something distinct and separate from the neighborhood or area residents, and to privilege what people in positions of power (city officials, real estate developers, etc.) say is “good” for the neighborhood rather than prioritize resident-led neighborhood improvements.
New MySpace
First, in case you missed it, here’s the video demo of what New MySpace will supposedly be like. (Beginner Sociologist Exercise: count the women and people of color shown as you watch the video; Advanced Sociologist Exercise: count the women who aren’t sexualized, and the people of color who aren’t entertainers; Both: compare with the front page for ‘old’ MySpace, which does still exist for now). The mostcommonreaction to New MySpace from the not-so-social media sphere seems to be twofold: 1) that New Myspace looks a lot like Pinterest, and 2) that a “bringingsexyback” joke is just dying to be made, given Justin Timberlake’s prominence both in the demo video and behind the scenes as an investor.
Aesthetics aside, my personal take—which is perhaps unsurprising, given what I’ve written aboutpreviously—is that New Myspace is aspiring to be your one-stop Facebook and Spotify shop, with some Twitter-style fetishization of celebrity thrown in for good measure. The interesting thing here is that, while New MySpace seems to be specializing in big-name celebrities, MySpace has historically been home to a wide range of smaller-name, unsigned music acts—and as such has built up a substantive library of files that most other music services don’t have; in fact, MySpace holds nearly three times as many titles overall as does Spotify. This means that MySpace’s strength as a music-oriented site or service is in an area that I think is one of Spotify’s biggest weaknesses: bands that are obscure and/or unsigned. This also gives New MySpace a lot of potential leverage in terms of subcultural capital; whether all this raw material for subcultural capital is part of MySpace’s ‘historic legacy’ or just (re)gentrification bait is…a grey area that I’ll develop a bit more below.
But anyway, let’s take a closer look at what tech commentators are saying about New MySpace. Slate’s Will Oremus states that New Myspace is “a step further away from its roots as a one-stop social network for the masses… Instead, it’s going to focus more narrowly on becoming a social home for musicians, artists, celebrities—and their fans.” Oremus appreciates the irony of the fact that he finds New MySpace to be “cleaner, simpler, [and] more aesthetically appealing” than Facebook, but he’s so eager to denigrate “the masses” of (present) MySpace that he’s forgotten how foundational music and music culture were to old MySpace (a point on which boyd elaborates in her chapter).
The Huffington Post’s Dino Grandoni, on the other hand, recognizes that “Artists, in particular musicians, were among the first to pioneer the social network before it reached wide popularity — and among the last to stay after Facebook overtook Myspace in unique visitors in 2008,” but he too emphasizes how “sleek,” “sexy,” and “beautiful” New MySpace looks, in an unspoken comparison is to the user-modified profile pages of old MySpace. Rebecca Cullers at AdWeek agrees that New MySpace is ‘bringing sexy back’; she finds that sexiness to be a welcome improvement over “the glitter unicorn backgrounds that made the interface impossible to view or navigate,” and “the crappy logo that we all knew was just lipstick on a pig.” The Associated Press, too, thinks New MySpace is “beautiful,” and speculates that “[New] Myspace wants to win the hearts and minds of tech-savvy hipsters.” “The video promises that Myspace will start ‘totally from scratch,’” the AP adds, “as if trying to shed its former self.”
Hipster?
It seems some things haven’t changed since boyd was doing her research; the consensus here is that old MySpace was ugly and unsophisticated, present MySpace is irrelevant and unworthy of attention, and New MySpace is sexy, savvy, modern, clean, and clearly aesthetically superior. If old/present MySpace is a run-down urban ghetto, New MySpace is a set of slick LEED-certified postmodern condos; Facebook, on the other hand, stands to be cast as a soulless sea of split-level ranch homes sprawling across the flatland plains of LowerMiddleClassville.
What really got me in the coverage of New MySpace, however, was Bob Moon’s segment on the American Public Media show Marketplace. I’m reproducing the last chunk of it below, because it’s worth taking a closer look at:
Myspace is aiming to refashion itself as a slick destination for emerging musicians to get exposure and stay in touch with their fans. Sandoval doesn’t rule out a slim chance the strategy could work, mostly thanks to Justin Timberlake’s contribution as an “entertainment phenomenon.” As a musician, actor and TV comedy star, Timberlake could reach multiple audiences and bring the site a lot of attention, says Sandoval. “You never know what somebody like him can do.”
At the research firm GigaOM, tech analyst Michael Wolf says Myspace faces an uphill battle against Facebook. He also points out that Facebook’s popularity means it can’t make changes as dramatically as Myspace, which has only a tiny fraction of Facebook’s global audience.
“You don’t want to alienate that large installed user base,” Wolf says of Facebook. “That’s one of the things that Myspace has in its advantages. They can take swings for the fences.”
In the end, that may be all the planned redesign turns out to be — another swing at saving Myspace. This is the site’s fourth major overhaul, and CNET’s Sandoval says if it weren’t for the star power of one of its backers, most people would just write Myspace off — as many already have.
There are three things I want to highlight here in order to make the case for New MySpace as (re)gentrification:
First, remembering that old/present MySpace is the urban ghetto, we have Justin Timberlake as the rich developer (and possible ‘white savior’) who’s going to swoop in and save ‘the neighborhood’ from decay (irrelevance, business failure) by rebuilding it in his own image—by (re)gentrifying, by remaking MySpace into a site geared more explicitly toward the urban upper-middle classes. No longer will MySpace be blighted by bling; the decaying profiles of (present) MySpace will be razed so that New MySpace can start “totally from scratch” (as the video says), can somehow be reborn as simultaneously sexy and safe, both edgy and clean.
Old MySpace profile page
Second, MySpace is planning to remake itself by appealing to musicians and music communities (the “storm troopers of gentrification”) in the hope of triggering network effects once again—but this time to bring people back into MySpace. Though many musicians are still active on (present) MySpace, 60% of them linger there in the hope of being discovered; as anyone who’s ever been part of a music scene can tell you, most musicians are not living the glamorous Life of Timberlake. The existing batch of bands may have some subcultural appeal, or appeal to members of their members’ own racial and/or socioeconomic groups, but the user base MySpace is trying to recapture with ‘New MySpace’ is in large part the more affluent group that left during the ‘white flight’ phase. These aren’t the people who are struggling to ‘make it’ as musicians; to quote one of boyd’s informants, they’re the people who go to “the other side of the tracks” for fun, but who “wouldn’t want to live there.” They might like the idea of musicians and music, but they don’t want to live in those so-called ‘up and coming’ or “transitional” neighborhoods where musicians live in group houses next door to ‘ethnic families’; they want to be close (but not too close) to an excitement that’s tamed and contained, a wild night out and a safe stumble home.
Third—and I think this is the most telling part—look closely at what the commentator from GigaOM has to say about the (present) MySpace and Facebook user bases. Facebook’s user base is not only still large, it is also still valuable; Facebook can’t afford to make drastic changes because it would risk losing something of worth. MySpace, on the other hand, can take risks—can “swing for the fences”—because it has nothing to lose; its user base is not valuable, does not have worth. How much worse could it get for MySpace, really?
Stop for a moment and consider the fact that—although another GigaOM writer couldn’t begin to fathom why this might be the case—(present) MySpace had more active users than either Tumblr or Google+in January of 2012. In 30 days spanning January and February of 2012, (present) MySpace added a million new users. The “tech-savvy” may not be paying attention to (present) MySpace, but that doesn’t mean the site is dead; in fact, it looks like MySpace is slowly growing. Recall that, as boyd points out, it’s not that “no one” is on MySpace anymore; it’s that most middle-class white journalists (and their friends) are not on MySpace anymore. Shocking but true: there is a whole wide world outside white middle-class journalists’ social circles.
True, MySpace still has only a fraction of the users that Facebook has, but does that make its roughly 262 million person user base expendable and not worth anything? It seems that while there are still plenty of people on (present) MySpace, they aren’t the people who matter—at least to the tech-savvy media community. The people who “matter” are the ones who left between 2006 and 2009, the ones New MySpace is trying to entice back in order to help (re)gentrify the neighborhood and ‘revitalize’ the site; after all, “most people” would write off (present) MySpace if it weren’t associated with “Mr. Sexy Back” himself. Here, ‘most people’ codes not only for “most of the people Bob Moon knows,” but the people who matter most to advertisers: middle-class and affluent mainstreamers who have enough discretionary income to spend money on concerts, nightlife, and (yes) $5 lattes and cupcakes.
Starbucks: Not In My Backyard.
Conclusion
I think it’s safe to say that, yes, New Myspace does look an awful lot like (re)gentrification. Though present MySpace is far from abandoned, it is frequently written off because 1) middle-class white journalists don’t usually know anyone who’s still part of MySpace’s more working class and more racially diverse user base, and 2) its existing user base isn’t ‘valuable’ to advertisers. Just as a poor neighborhood frequently gets neglected by city government because it doesn’t bring in enough tax revenue, (present) MySpace’s days are numbered because its user base isn’t seen as a valuable asset. A ‘revitalized’ neighborhood brings in more tax revenue; a (re)gentrified New MySpace will bring in not only more user-data and attention, but user-data and attention from the ‘right’ kinds of users—or so investors in the site are hoping.
I’ll stop here and state the obvious: yes, MySpace is a business. It is not a city government. It has no obligation to care for or to care about the users of (present) MySpace, and getting displaced out of a social networking site is not exactly like getting priced out of a neighborhood. Still, we should be asking what will happen to the existing communities on present MySpace—and we should ask why this issue is so completely absent from the glossy New MySpace demo video. Social media is not a separate world; it is a part of this world and, as boyd argues, the inequalities that get reproduced in social media are some of the same inequalities that we must still work to address.
Whitney Erin Boesel (@phenatypical) still has a profile on MySpace, but admits she had to have her password reset in order to log in and poke around for this post.
“Mindfulness” may be Quantified Self’s best-kept secret.
Before the dust of Quantified Self 2012 (#QS2012) settles completely, I want to take a moment to reflect on an implicit question that I saw running throughout the two-day conference: If data empowers individuals, what kinds of information do and do not count as data?What kinds of information have value, and to whom?
The idea that data[i] empowers individuals was well-represented at both #QS2011 and #QS2012; indeed, it has been a consistent theme within Quantified Self from the group’s beginning. Last year at #QS2011, the question I observed coming up most frequently was the question of how to make that empowerment happen: “What do I do with all this data now that I’ve collected it?” The “how” question remained alive and well at #QS2012, but this year another question seemed to come up again and again (if in different terms): What kinds of information are valuable? What kinds of data “count”?
Self-Quantification Type A: Larry Smarr says, “Actually Measure!”
This new question was more often implied than stated directly, but it kept coming up—for instance, in the quiet tension between some of the featured show-&-tell presentations. On the one hand, there was Larry Smarr’s (@lsmarr) surprisingly entertaining talk [video link will appear here once available] about how he discovered his Crohn’s disease well before his doctors did. The moral of Smarr’s story was classic QS: don’t trust diet books, don’t trust your doctors, and don’t trust how you feel. You can’t know for certain that you’re healthy unless you “actually measure,” by which Smarr meant ‘measure with laboratory tests’—and in his own case, quite a lot of them (most of which he ordered, and paid for, himself). In Smarr’s case, the data that was valuable to him was produced by laboratory technicians who performed tests on Smarr’s blood and stool samples. Smarr was empowered by interpreting this data himself, with the help of scientific journal articles (and later, a sympathetic gastroenterologist). “Doctors should be asking, ‘What are your numbers?’ not ‘How do you feel?’” Smarr said. “The idea that you can feel what is going on with you is so epistemologically incorrect.”
Self-Quantification Type B: Nancy Dougherty’s flashing LED mood feedback device
On the other hand, a major theme of #QS2012 was mindfulness—the idea that the awareness one develops through self-quantifying may be as beneficial as (if not more beneficial than) the collected data itself. In another show-&-tell presentation, Nancy Dougherty (@nancyhd) explained [video link will appear here once available] that simply tracking her emotions had changed her emotions for the better, and that it was through emotion tracking that she discovered mindfulness. As a result, she designed a device to reflect her moods back to her in the moment as well as log data for her to analyze later.
Similarly, Alan Greene (@drgreene) described a patient encounter with a young boy who, though blind since birth, could tell that Greene was smiling at him—and was moved to tears by it. Greene was moved by the interaction as well, and became inspired to start cultivating his own intuitive sense of other people’s emotions. After a few months of practice, he found that by carefully observing his own emotions both immediately before and immediately after entering an examination room, he could do a pretty good job of figuring out how his patients were feeling. In his experience, being able to say not just “How are you feeling today?” to his patients, but “Seems like you’re feeling tired today,” had resulted in better doctor-patient relationships (and perhaps better treatment outcomes).
Alexandra Carmichael (@acarmichael) had said while introducing Dougherty’s talk that, “QS is a very mindful community,” and several of the #QS2012 attendees I spoke with over the weekend readily concurred; some QSers even cited mindfulness as the primary benefit of self-quantifying. In one session I attended, a young man said that—although he hadn’t believed it when more experienced self-quantifiers told him this would be the case—he’d found that all the positive changes he’d made through self-quantifying came from developing mindfulness. With what seemed like a tinge of chagrin, he that admitted that hadn’t learned much of anything from pouring over his self-tracking data in and of itself.
Trust the person, or trust the data?
The most interesting discussion in this vein, however, happened during Yuri van Geest’s (@vangeest) session, “Psychological and social-cultural consequences of QS going forward.” Van Geest mentioned that GPS devices have been posited to weaken people’s sense of direction, and asked the crowded room, “If you outsource your awareness to technology, do you risk losing your intuition?” One woman responded that she was a patient at a fertility clinic, and as such was now engaged in extensive self-quantifying as part of her efforts to conceive. She’d found that self-tracking had actually strengthened her ability to tell when she was ovulating, but she had a different problem with technology: when her ‘mindfulness’ about her body indicated she was ovulating, but the ovulation predictor tests provided by the clinic indicated she was not, the clinicians sided with “the stick.”
Small sticks speak loudly.
Each and every time the woman insisted the clinic run additional tests, however, ultrasound imaging showed that she was indeed ovulating: it was the woman who was correct, not the stick. Despite this, the clinicians continued to privilege (so-called) objective, quantified device-knowledge over her meticulously tracked but more qualitative self-knowledge until an expert (the clinician) and another device (the ultrasound machine) produced device-knowledge that validated the woman’s self-knowledge. Her problem then was not that technology (the stick) had weakened her intuition, but that technology “interfered with [her] ability to communicate with the clinic.” Put simply, the stick spoke more loudly than she could—and as a result, the quantified self-knowledge she produced by using the stick disempowered rather than empowered her in her relationship with the clinicians.
Later that afternoon in the closing plenary [video link will appear here once available], Kevin Kelly (@kevin2kelly) stated that, “information that can be quantified can be shared with others.” (Kelly, of course, takes ‘sharing with others’ to be a good thing, because it is only through pooling data into a vast “data commons” that revolutionary breakthroughs in healthcare and self-care will be achieved.) I thought about The Woman vs. The Stick, however, and came to a somewhat different conclusion.
Kevin Kelly at Quantified Self 2012
Yes, quantified (device-gathered) (laboratory-produced) data can be shared with other people. But qualitative or observational data can be shared with other people, too. The ease or difficulty of sharing data with other people is not an inherent property of the type of data; rather, it is a function of social and cultural ideas about what kinds of information are valuable or trustworthy. Remember: claims about ‘truth’ are always claims to power. The difficulty of sharing non-quantitative data has little to do with the data sets themselves, and has much more to do with our dominant epistemologies; it is not that some types of data can’t speak, but that some people in power refuse to listen. The problem isn’t the data; the problem is the people.
I think some of these perspective differences within Quantified Self stem from the different reasons people get into self-quantifying. Perhaps some who begin self-tracking because of a serious medical illness are more likely to privilege test-produced knowledge, while others who begin self-tracking out of curiosity or for general self-improvement might be more willing to privilege experiential, intuitive, or qualitative self-produced knowledge. This is just an initial hypothesis, and I’d be interested to know if others have different ideas. In any case, the latent tension between the “don’t trust how you feel, that information will lead you astray” and “develop an awareness of how you feel, this information is critically valuable” messages within Quantified Self are something I’ll be paying attention to as I go forward with my research.
Whitney Erin Boesel (@phenatypical) co-hosted the breakout session at #QS2012 for academics doing research within the Quantified Self community, and is looking forward to #QS2013 in Amsterdam next May!
[i] USAGE NOTE: I’m aware that “data” is supposed to be a plural noun (not a singular one); I’m also aware that language is constantly evolving. A number of mainstream journalism outlets have decided to let singular “data” stand, and—though as a former writing major, I’m tempted to insist that data is and forever will be plural and plural only—I’ve used it here as a singular noun throughout in order to reflect what seems to be correct usage within the QS community.
Can we create quantitative data that will help us make sense of our emotions?
In preparation for the 2012 Quantified Self Conference on 15 and 16 September (#QS2012), I’m spending a couple weeks writing about the “self knowledge through numbers” group Quantified Self. Last week, I focused on self-quantification in relation to my masters work on what I’ve termed biomedicalization 2.0; this week, I focus on my upcoming dissertation project, which will look specifically at emotional self-quantification (or “mood tracking”).
What is mood tracking?
I became aware of mood tracking—in the self-quantification context—while I was at the first Quantified Self Conference, which took place in Silicon Valley in May of 2011. I attended some of the “lunchtime ignite talks,” and happened to catch Sarah Gray presenting on MercuryApp. Gray initially created MercuryApp (which tracks emotions for the purpose of decision-making) for herself, while she was in a long-distance relationship. She thought the relationship was great, but she and her partner were having difficulty figuring out which one of them should move. Gray created the app, used it to track her feelings about her relationship for two months, and then took her first look at the data she’d accumulated. The results surprised her: she wasn’t nearly as happy in her relationship as she thought she was. Instead of moving, or helping her partner to move, Gray broke off the relationship because of what she saw in her mood tracking data. “One sad panda you can write off,” she said in her presentation, “but many sad pandas?”
Sarah Gray talks about MercuryApp at #QS2011.
Here’s the disclaimer paragraph: mood tracking is, of course, not new. Psychologists, psychiatrists, and other mental health professionals have asked their patients to mood track as part of treatment for some time (though generally in ways that seem much more medicalized and much less user-friendly [pdf] than a touchscreen mobile app full of smiling and frowning pandas), and individuals have tracked their emotions independently (in both direct and indirect ways) through practices like journaling and diary-keeping since well before Freud. I should also note that a self-tracking tool is not automatically a tool for self-directed self-quantification just because it’s “an app”; present-day self-tracking apps map onto a continuum from medicalization to biomedicalization to biomedicalization 2.0, and mood tracking apps are no exception. A mood tracking app may be designed to collect data at a healthcare provider’s behest (medicalization), to collect data about which you’re then encouraged to ‘talk to your doctor’ (biomedicalization), or to collect data for which you yourself will be the primary sense-maker (biomedicalization 2.0).
So what do I find so interesting about mood tracking that I’m planning to do an entire dissertation about it? Below, I’ve sketched out preliminary versions of my three primary research questions; comments and questions are encouraged!
1.) What kinds of knowledges are produced through self-quantification, and through emotional self-quantification specifically? What ways of knowing—about ourselves and about the world—are opened up, and which are foreclosed? People are meaning-making creatures; we make sense of our worlds, our lives, and ourselves by creating narratives based on the information (broadly defined) available to us. What kinds of stories are easier to craft from which kinds of quantified data, and which kinds are more difficult? What kinds of frames or settings are implicitly encouraged when we use specific self-quantification tools, or when we self-quantify at all? What can we learn from self-quantification that would be much harder, if not impossible, to learn in other ways? What might self-quantification render much harder, if not impossible, to learn? What are the larger social and political consequences of embracing self-quantified ways of knowing?
Quanting emotions can get much more complicated than you might think.
As Gary Wolf (@agaricus) illustrates, mood tracking is a lot more complicated than it might seem on the surface; it doesn’t just boil down “too many sad pandas = leave your partner.” The conclusions we might draw from mood tracking are influenced by what kind of data we gather, how we gather our data, and what frameworks we use to determine what counts as data, as well as by the questions we ask (and how we ask them, and for whom we ask them) when we sit down to make sense of that data. Furthermore, as Arlie Hochschild argues, emotions are social even when we experience them privately. How we interpret our feelings, how we feel about our feelings, and which feelings we think we’re supposed to feel in any given moment or context are all profoundly influenced both by identity and by culture; similarly, our feelings serve as important tokens of exchange in our relationships with others. Which aspects of the often-overlooked sociality of emotions are captured by different mood tracking practices? How does this affect what we learn from mood tracking?
2.) How does self-quantification compare to other forms of self-documentation, both public and private or digital and analogue? Around Cyborgology, we pay a lot of attention to self-documentation in the public and digital sense (for instance, what people chose to ‘reveal and conceal’ about themselves, and to whom, on social networking sites). Others have studied self-documentation in the primarily private and analogue sense (for instance, diary-keeping and journaling). Emotional self-quantification with mood tracking apps straddles both these loose categorical binaries: the data people generate about themselves is shaped by the affordances of different digital interfaces (as is, say, your self-documentation on Facebook), but that data is generally not meant for public consumption (eg, you might think about someday putting together a presentation on your mood tracking project for a Quantified Self meetup, but there’s a good chance you’re the only person who will ever see all of your raw data).
You?
Of course, not all mood tracking is private, but that doesn’t make it public either. The most recent version of Mood Panda (yes, there’s more than one app in which you can be a ‘sad panda’) integrated a social sharing aspect and found that, while a number of people were eager to share their mood tracking with others, they were not particularly eager to share their mood tracking with people who knew them in any other context: only 35% of Mood Panda users used Facebook integration features, and a mere 2% use Twitter integration to cross-post there. This is interesting to me because it highlights the fact that “private” doesn’t always mean “alone” or “self-only,” just as “public” doesn’t always mean “visible” or “readily identifiable” (see also: the practice of keeping alternate social media accounts that are not access-restricted, but which are also not connected to a one’s main account or to any of one’s friends’ accounts).
3.) What does the growing popularity of emotional self-quantification tell us about the current historical moment? (Why quantification, and why now?) Emotions have confounded human beings since human beings have had emotions, but human beings have not always tried to make sense of emotions through numbers. Though emotional self-quantifiers are still in the minority (as a percentage of the overall human population), interest in emotional self-quantification is growing; we could also look at the number of different mood tracking apps available and ask why at least some people expect the interest in mood tracking to grow (else why have a start-up that makes products for mood tracking?). Alexandra Carmichael (@acarmichael) complied a list of more than 20 mood-related self-tracking tools, and that was just in 2010. At least 10 different presentations [pdf] discussed mood or emotion tracking at the 2011 Quantified Self Conference; as one attendee quipped, “This year’s cow bell = mood apps at #qs2011… every other poster/app is a mood tracker.” (Check back next week for my report on mood tracking at #QS2012.)
Is ‘quantified vision’ presently inevitable?
The easy answer here is to throw out something about ‘big data’: computers made big data possible, personal computers made personal digital data possible, and now in the era of Really Big Data (a ‘data deluge’, in fact), ‘personal profiles’, ‘ubiquitous computing’, and ‘a gene for’ just about everything, of course we’re drawn to turn a quantified gaze inward in order to make sense of ourselves in the world (or as the world?). I don’t think it’s that simple, however; I think there’s a lot more going on both with self-quantification generally and with mood tracking specifically, and that the whole picture is probably a lot more complicated, nuanced, and messy. And hopefully I’m right about this, or I’m in for a very boring dissertation! (I’m not concerned.)
Whitney Erin Boesel (@phenatypical) will be co-leading a breakout session on academic research and self-quantification at #QS2012.
In preparation for the 2012 Quantified Self Conference on 15 and 16 September (#QS2012), I’ll be spending the next two weeks writing about the “self knowledge through numbers” group Quantified Self (@QuantifiedSelf). This week, I focus on self-quantification in relation to my masters work on what I’ve termed biomedicalization 2.0; next week I’ll focus on my upcoming dissertation project, which will look specifically at emotional self-quantification (or “mood tracking”).
What is biomedicalization 2.0?
In 2003, Clarke, Shim, Mamo, Fosket, and Fishman [paywall, sorry] proposed biomedicalization as a way to describe “the increasingly complex, multisited, multidirectional processes of medicalization, both extended and reconstituted through the new social forms of highly technoscientific biomedicine.” Beginning around 1985, and against the backdrop of late modernity, biomedicalization emerged as technoscience was increasingly incorporated into medicine. This incorporation changed not only the practice of medicine, but also the process of medicalization. Biomedicalization furthered the expansion of medical authority into more areas of human life, and reorganized the institution of biomedicine “from the inside out.”
In 2012, against the backdrop of ‘the digital age’, ‘the post-genomic era’, a ‘post-privacy world’, and a ‘postindustrial society,’ I argue that we are seeing the emergence of a new form of biomedicalization, one that I wryly term biomedicalization 2.0. With “biomedicalization,” I reference Clarke et al’s theory of biomedicalization and signal the ways this new form mirrors and extends the process of biomedicalization. With “2.0,” I reference the technical convention for distinguishing a new version from its predecessor, as well as the emphasis on ‘a new paradigm’ that characterized the much-hyped announcement of ‘Web 2.0’ in 2004. Biomedicalization emerged from the coalescence of major technoscientific changes within the medical sphere[i]; biomedicalization 2.0 is similarly emerging as recent technoscientific innovations converge with venture capitalism, technoutopian cyberculture, and the digital economy at sites outsideof biomedicine’s jurisdiction. Where medicalization and biomedicalization extend the range of medical authority by extending the range of medical practice, biomedicalization 2.0 challenges medical authority through ‘medical’ practices that have been resituated in contexts outside of institutional medicine’s oversight and control.
I use the term extramedical to describe those areas which remain outside of institutional biomedicine’s expanded and expanding authority, and I argue that the convergences described above constitute an amorphous, decentralized extramedical sphere. I further argue that the institutions and individuals within the extramedical sphere expand the extramedical domain by claiming authority within territories of knowledge and practice previously claimed for the exclusive medical domain. Extramedical expansion is inclusive rather than exclusive, however, and aims not to supplant the medical sphere as sovereign within claimed territories, but to replace state-supported sovereignty with ‘free market competition’ by removing claimed territories from the medical domain altogether. By claiming ‘medical’ territories as ‘not-medical,’ extramedical actors bring the very meaning of the word “medical” into question. These jurisdictional and semantic-taxonomic challenges have the potential to disrupt the organization of institutional biomedicine once again, not “from the inside out,” but from the outside in.
Below I offer a basic crash-course for readers who may not be familiar with sociological work on medicalization and biomedicalization, then elaborate on biomedicalization 2.0 by considering the Quantified Self groups as an example of biomedicalization 2.0 in action.
Biomedicalization 2.0 is a challenge to institutional medicine.
So what are medicalization and biomedicalization?
Sociologists use the term medicalization to describe both the increased investment in institutional medicine (or the medical industrial complex) that began in the years following World War II, and also the related phenomenon by which medicine and medical labels (such as “healthy” and “ill”) become newly applicable to more areas of human life. Most generally, medicalization represents the expansion of medical authority through the claiming of new things as medical events or medical problems: some classic examples are birth and death (which used to be ‘natural life processes’ that happened at home, but which now typically happen in hospitals and with medical intervention), or alcoholism and other addictions (which used to be seen as character flaws, but which are now largely recognized as ‘diseases’ instead).
It’s important to note, however, that this expansion isn’t uniform. Ehrenreich and Ehrenreich identify the expansion of medical authority and control as cooptative medicalization, one of medicalization’s two dual tendencies; the other is exclusionary medicalization, the process by which access to and quality of available healthcare is stratified according to patients’ abilities to pay. Medicalization brings more areas of human life into institutional medicine’s control, but it also excludes more individual humans from the newest services and interventions.
Biomedicalization is Clarke et al’s term to describe a process that began around 1985, and that changed the character both of institutional medicine and of medicalization. What happened is that interrelated technological developments and social changes that had been accumulating over the course of medicalization reached a kind of critical mass, and transformed institutional medicine (or biomedicine) “from the inside out.” Transformation is a key theme within biomedicalization, as new technoscientific innovations enable the practice of medicine, the institutional organization of healthcare, and individual human bodies to be altered and metamorphosed in ways that would have been unimaginable even a generation ago.
Clarke et al emphasize that biomedicalization has not fully replaced medicalization—the two processes can and do occur in the same places and at the same times—but biomedicalization does represent a transformation of medicalization. Put very simply, biomedicalization continues to expand institutional medicine’s authority even further (particularly by claiming “health” as a site of medical intervention in addition to “illness”), but 1) the institution of medicine is changed (think individual doctor’s offices vs. the giant bureaucracy of an HMO), and 2) the process occurs in a wider variety of ways (for one example, think of your doctor telling you to lose weight vs. your friends trying to recruit you into doing a new fad diet with them).
Some of the major changes in biomedicalization involve issues of power and expertise. In biomedicalization, physicians and academic researchers find their influence and authority not only supplanted by corporations within the medical sphere, but also increasingly contested by patients and other lay individuals within the medical domain. Though patient advocacy groups first began to form in the 1970s, the advent of the Internet has enabled more lay individuals both to access an expanded array of previously restricted medical knowledges and to network and organize with each other. The number of support and advocacy groups has since expanded greatly, and a number of such groups are sufficiently powerful to lobby for changes in federal policy and to direct specific research projects through funding initiatives.
Not all of the changes within biomedicalization have empowered lay individuals, however. As patient groups gained political and economic power, agents within the medical sphere (such as pharmaceutical companies, physician organizations, and researchers) began to form their own ‘grassroots’ patients’ movements – which are sometimes called “Astroturf movements” by critics – in order to capitalize on a new avenue of influence. The increase in patients’ demands for more egalitarian and collaborative relationships with their physicians also fits synergistically with the ongoing devolution of healthcare, in which responsibility for much of the monitoring and care-giving labor of medical care is shifted from healthcare professionals to patients’ families or to patients themselves. Is this ‘empowerment,’ or something more like exploitation? Who benefits (and how) when patients “take more responsibility” for their health and healthcare?
Quantified Self co-founder Gary Wolf at #QS2011
What is the Quantified Self?
The Quantified Self exemplifies one of the things that I find most fascinating within biomedicalization 2.0, which is what I term chiasmata: unsettled and unsettling—yet potentially productive—relationships within the new blurred, hybridized, and seemingly contradictory concepts and identities that emerge within the extramedical sphere. I’m borrowing heavily here from Fortun’s Promising Genomics, in which he uses X, the chiasmus, to mark “couplet[s] of terms which are conventionally taken as distinct or even opposed, but that in fact depend on each other, provoke each other, or depend on each other.” I use the term chiastic identities to describe the similarly uneasy, unsettled, troubling-yet-promising relationships within new blurred and hybridized forms of subjecthood such as subjectXresearcher and subjectXconsumer. Though blurred conceptual boundaries (such as those between labor and recreation, or between production and consumption) are characteristic of postindustrial societies most generally, the chiastic identities of biomedicalization 2.0 both embody and reflect the tensions inherent in medicalization, biomedicalization, and biomedicalization 2.0, and pose questions that are not easily answered.
Self-quantifiers (or self-trackers) aresubjectsXresearchers because they are both the observers and the observed in their studies of n=1; they simultaneously occupy both positions in what is usually a relationship of unequal power, and in so doing conflate conceptual binaries around empowerment, agency, and exploitation. Although some people self-track at a doctor’s behest, and under a doctor’s supervision, others do so independently, or interact with doctors only as hired consultants rather than as authority figures; in this way, they challenge both traditional medical authority and the traditional doctor-patient power relationship.
Can self-directed self-tracking represent the potential for individuals to “take more responsibility” for their health in ways that might more closely resemble empowerment, rather than the devolution of healthcare? Before we can answer these questions, we have to decide what ‘empowerment’ really means (for whom, and in which contexts, and who decides?); we also need to ask who benefits, and how, when individuals are asked to “take more responsibility” for anything, or to focus on personalized rather than collective action as the path to “empowerment.” (I hope to take on some of these questions in my dissertation project, which I’ll talk more about next week.)
Self-knowledge through numbers?
Co-founded by Gary Wolf (@agaricus) and Kevin Kelly (@kevin2kelly), the Quantified Self is one of the largest groups of networked subjectsXresearchers. Though started in the Bay Area in 2007, it gained national attention in 2010 following Wolf’s New York Times Magazine article on “the data-driven life.” Wolf’s essay is a common (though not universally representative) narrative of self-tracking, one in which the archetypal self-tracker is indisputably an autonomous individual. In keeping with the technoutopian heterodoxy’s distrust of authority and traditional institutions, and in accordance with the extramedical sphere’s challenges to medical authority in particular, the self-tracker resists being controlled (and possibly harmed) by institutional biomedicine in part simply by refusing to follow medical advice.
The self-tracker is empowered to make this refusal not just by information, however, but by quantified self-knowledge: though his doctor may be the ‘expert’ on matters of medicine-most-generally, through technology-enabled observation and detailed, quantified records, the self-tracker is certain of being the expert on himself (I say “himself” here because the majority of self-trackers mentioned in the essay are men). Moreover, this refusal to accept medical authority is an act not just of self-preservation, but also of self-defense and political defiance in the face of “the imposed generalities of official knowledge.” The self-tracking subjectXresearcher is The Individual taking on The Establishment, one datum at a time.
Self-tracking, however, is not just an exercise in defying medical authority. The self-tracking subjectXresearcher also takes neoliberalism’s preoccupation with The Individual and turns it inward, onto his own individual self. While Quantified Self founders point to the benefits that self-tracking can have on both self-awareness and on relationships with others, these immediate personal relationships seem to be the blurry edge of a quantified field of vision. Even the self-tracker’s characteristic defiance of institutional biomedicine, it turns out, is less about rebellion or revolution; rather, it “shows how closely the dream of a quantified self resembles therapeutic ideas of self-actualization.” The self-empowerment of self-quantifying, it seems, has less to do with the individual in the world and more to do with the individual in his own interiority; it may be less about challenging older relationships of authority and expertise, and more about coming to terms with the world as it stands.
The archetypal self-tracker who emerges from the vignettes in Wolf’s essay does not, of course, represent all self-trackers, or even all self-trackers who are Quantified Self members. Yet, this un/intentionally polemicized figure of the subjectXresearcher highlights a different facet of biomedicalization 2.0: the ways in which preoccupation with ‘information’ and individual self-hood can potentially create subjects who are not empowered, but disengaged. This version of the self-tracking subjectXresearcher, pacified by the steady stream of information generated through daily practices, may get absorbed into the digitized abstraction of his own quantified identity. Is self-quantification a way to change the world, or a way to make peace with the world-as-it-stands? Can self-tracking individuals change the world if they all self-track together? I don’t yet have answers to these questions, nor do I think anyone else does.
Next week I’ll talk more about some of these issues, particularly as they relate to mood tracking and my dissertation project.
Whitney Erin Boesel (@phenatypical) will be at #QS2012 later this month. Come say hi!
[i] I use “the medical sphere” to denote the organizations, corporations, and individuals involved in or connected to the practice of institutional (bio)medicine, such as health management organizations (HMOs), pharmaceutical companies, physician organizations, academic research centers, healthcare and research professionals, etc. I use “the medical domain” to describe the realm of institutional (bio)medicine’s jurisdiction, and the areas within that realm over which institutional (bio)medicine claims exclusive authority (such as the diagnosis and treatment of disease, the manufacturing and prescribing of pharmaceuticals, the production and management of knowledges about the human body, etc.)
I’ve been thinking on and off since mid-summer about a hole I’ve identified in our collective theorizing of augmented reality. To illustrate it, imagine the following conversation:
Digital Dualist: ‘Online’ and ‘offline’ are two distinct, separate worlds! Me: That’s not true. ‘Online’ and ‘offline’ are part of the same augmented reality. Digital Dualist: Are you saying that ‘online’ and ‘offline’ are the same thing? Me: No, of course not. Atoms and bits have different properties, but both are still part of the same world. Digital Dualist: So ‘online’ and ‘offline’ are different, but not different worlds? Me: Correct. Digital Dualist: But if they’re not different worlds, then what kind of different thing are they? Me: …
I don’t know about you, but this is where I get stuck.
My thinking along these lines was first sparked by a tweet in which Nathan Jurgenson (@nathanjurgenson) reported that Rian van der Merwe (@RianVDM) had misread his IRL Fetish piece, and come away with the idea that Jurgenson “think[s] on/offline are the same.” That wasn’t my reading of the IRL Fetish essay, but I realized it wasn’t hard to see where van der Merwe might have gotten that impression if he wasn’t already coming from an augmented reality perspective.
I’ve since gone back through a lot of writing on digital dualism and augmented reality (both on Cyborgology and elsewhere), and come to the conclusion that while Team Augmented Reality does a great job of explaining the enmeshment of ‘online’ and ‘offline’, and what the difference between ‘online’ and ‘offline’ isn’t, we need to do a much better job of explaining clearly what the difference between ‘online’ and ‘offline’ actually is. While the precise nature of the difference may not need to be spelled out for those of us who already embrace an augmented reality framework, not spelling it out leaves too much room for misreadings and misinterpretations of our work. If we want to make a dent in pervasive digital dualism, we need to address this theoretical hole.
Below, I review some of what’s been written about digital dualism and augmented reality, as well as what’s been written about the differences between ‘online’ and ‘offline’; I then pose some of my lingering questions. It’s my hope that this post will start a conversation that will strengthen all of our work within the ‘augmented reality’ framework by helping to clarify our terminology.
A beginning.
Jurgenson first coined this usage of the term “augmented reality” in 2009, but most of us at Cyborgology tend to reference this 2011 post in which Jurgenson states,
I am proposing an alternative view that states that our reality is both technological and organic, both digital and physical, all at once. We are not crossing in and out of separate digital and physical realities, a la The Matrix, but instead live in one reality, one that is augmented by atoms and bits.
In the tradition of much post-Modern theorizing, “augmented reality” offers a new conceptual paradigm, seeking to implode/queer/do category work on the real/virtual dichotomy and make room for a more flexible understanding of social media that allows for recursivity between these two concepts. …However, the symbolic order expressed through the digital does not emerge out of nothing; it is a reproduction or extension of what has always existed. The digital and material are always in circulation and neither can be abstracted from the new order of social relations. That is to say, society is neither online or offline; it is augmented. Thus, augmented reality and the cyborgs who populate it are now the proper objects of sociological inquiry.
Reality is augmented—characterized by the entwinement of human and technologies rather than their categorical separation. Digital and physical, online and offline are false dichotomies that the bloggers here at Cyborgology actively work to blur.
The digital and the physical are thoroughly and inextricably enmeshed.
But now that we’ve made the case for the inseparability of ‘online’ and ‘offline,’ how do we describe the ways in which the two remain different, if not entirely distinct from each other? If the two aren’t different realities, and aren’t different worlds, what sort of different things are they?
Discussion of the ‘difference’ within augmented reality has most often focused not on differences between online and offline, but on differences between “the digital” and “the physical” (which I see as a closely related set of differences, but not the same set of differences). These differences are most often boiled down to the differences between ‘atoms’ and ‘bits,’ which in Jurgenson’s words “have different properties, influence each other, and together create reality.” He has also recently clarified that,
[T]he digital and physical are not the same, but we should aim to better understand the relationship of different combinations of information, be they analog or digital, whether using the technologies of stones, transistors, or flesh and blood. Also, technically, bits are atoms, but the language can still be conceptually useful.
Bits are easy to copy while preserving their full organization, atoms are not (in other words, in the online world we have whatever Scotty in Star Trek used to beam people up by deconstituting them molecule by molecule and reassembling them someplace else. (Oops, if you are in an industry where your product is in bit form). Bits travel much easier than atoms, making bits much harder to censor and isolate (I’m looking at you, Mubarak). The architecture in the online world depends on the underlying code while the architecture of the offline world depends on laws of physics. Hence, online, we don’t have the same balance of privacy and visibility that come from the physical properties of space and time: that offline speech disappears after it is uttered; that, offline, we can usually see who is looking at us; offline walls, doors, locks and windows operate in a predictable manner. (That is why Facebook can be so jarring at times: it often ignores deeply ingrained cultural conventions based on laws of physics. It puts all your friends in the same room, by default–and its new timeline defies rules of flow of time as we knew it).
…There is certainly a difference between emailing someone and, say, sitting in a cafe by the Bosphorus; however, I am not able to categorize it merely as one is good/the other is bad. Each form has strengths and weaknesses depending on the topic, person, location, moment… Some things are better discussed over email. But sometimes you need to be able to hold out a hand.
[T]he term augmented reality does not need to imply that the differences between atoms and bits does not matter. Quite the opposite because we cannot begin to describe these differences until we start with the assumption of augmented reality. We cannot adequately discuss one without taking into account the other’s at least partial influence. Simply put, the assumption of augmented reality makes possible the very discussion about the relevant differences between atoms and bits that Sang (and myself) wants to have. [emphasis mine]
Perhaps this, then, is the problem. As we’ve worked to establish augmented reality as a theoretical paradigm, we’ve argued: 1) that the physical and the digital are different because atoms and bits are different; 2) that the atoms/bits difference is important; 3) that the atoms/bits difference is not one of good vs. bad. We’ve stopped short, however, of theorizing these admittedly important differences, and instead cited the undertheorized differences between atoms and bits as evidence for why the augmented reality perspective is necessary. This is a valid point; we do need to understand augmented reality in order to understand the relationships between atoms and bits, between ‘the digital’ and ‘the physical,’ between ‘online’ and ‘offline’. What remains now is for those of us who have adopted the augmented reality framework to start “the very discussion” about what those differences are.
We still have work to do…but that’s why we do this, right?
If we start by more extensively theorizing the differences between atoms and bits, what will that tell us about the differences between ‘the digital’ and ‘the physical’? Will that shed light on the differences between ‘online’ and ‘offline’? What kinds of differences are these? And while we’re at it, what kinds of things are these (for lack of a better term)?
In my (probably incomplete) survey of writing on augmented reality and digital dualism, the word most frequently used to describe ‘the digital’ and ‘the physical’ is spheres. These spheres are “very different,” but absolutely “notseparate [.pdf],” and thoroughly “enmeshed”—but if we’re going to be concrete about it, what exactly is a ‘sphere’? What’s that supposed to mean, and how do you explain it to the hypothetical Digital Dualist in my opening dialogue? [Full disclosure: I use ‘sphere’ terminology all over my own work, and—though I have a footnote definition I use in papers—I often use ‘sphere’ terms without explanation when I talk about my work; I’m as guilty of this as anyone.] ‘Sphere’ may mean something self-evident to a bunch of theorists, but it isn’t going to make much headway in countering popular digital-dualist conceptions of the world.
“Space” and “environment” have also been used (the former perhaps more metaphorically than the latter), but spatial metaphors can be a slippery slope; how clear are the lines between ‘a space’, ‘a place’, and ‘a world’? Relatedly, Malcolm Harris (@BigMeanInternet) recently described Twitter as “a territory… a global city” that he named Twitterland; Jurgenson countered that Twitter is not a new city, but rather a part of the same cities that we’ve had since before we had Twitter. “The power of new technologies Harris is describing are precisely born of the fact that they are not, as the title of the story suggests, of a ‘Twitterland,’” Jurgenson argues; rather, “[t]he power-grabs in play are those of one reality, one of physical space, material inequalities, bodies that hurt, people with histories, pains, pleasures, re-networked together.” While this poetic description illustrates why Twitter (and by extension, ‘the digital’ or ‘the online’) isn’t a new or separate place, again we have to ask the question: when we consider these great unwieldy assemblages of people and power and politics, of technology and information and affect, of everything else that makes up an augmented world, what is it that we’re looking at?
If ‘digital’ isn’t a place or a world or a reality, can it be a practice? A mode of engagement? A way of being, or an orientation? Can ‘physical’ be each or any of these things? What are the stakes and implications for each possibility? What does it mean if we agree ‘digital’ can fall into a category that ‘physical’ cannot, or vice versa? And critically, why are we limiting ourselves with dualist framings by implicitly accepting that whatever the applicable categories are, there are only two designations: “digital” and “physical”? What happens if we push past binary logic in our critiques of digital dualism?
It also seems clear that ‘digital’ is the marked category, and that whatever kind of thing it is, ‘not digital’ is such only by implication or association; ‘online’ is the Other without which the Subject (the dualists’ supposed ‘offline world’) cannot define itself. This highlights an additional problem (one among many, really), which is the way the term ‘physical’ implicitly becomes a catchall for all the things and kinds of things that are not already marked as ‘digital’. Some things are neither digital nor physical; thoughts, sensations, power dynamics, *-isms (to name just a few) may have both physical and digital manifestations, but don’t fit neatly into either designation. If our goal is to understand our (augmented) world, we do ourselves a disservice by lumping all of its non-digital aspects under ‘physical’. As we work to better theorize the differences between atoms and bits, can we consider as well the differences between those things that are neither? Or those things that might be both?
Let’s think even further outside the box.
As I’ve said, these are just some preliminary thoughts—but I hope to stir up more conversation on these topics, and to push more of us into taking on the task of theorizing categorical difference within the augmented reality framework.
Whitney Erin Boesel (@phenatypical) will theorize with you on Twitter if you *ping* in her direction.
Networked relational spaghetti? Below: how to read this graph.
Before the 2012 meeting of the American Sociological Association kicked off last week, I challenged those of us who tweet at conferences—or “backchannel”—to reach out to those who don’t. (Nathan Jurgenson has since made a convincing argument for why ‘backchannel’ isn’t the right word for this practice, though I’m not yet aware of a good replacement term.) This week, I want to share some of my preliminary observations and questions about gender and Twitter use at ASA2012 by looking at Marc Smith’s (@marc_smith) Twitter NodeXL social network analysis maps.
So first off, what are we looking in the graph above?
The picture above is really just a snapshot of the network graph itself—or as Marc explained to me yesterday at the University of Maryland Summer Social Webshop, “a snapshot.” The picture is there to be a teaser, a taste of what NodeXL users can do if they download the same spreadsheets of data (which Marc makes available at the bottoms of his graph pages). Marc includes an explanation of how to read his graphs with each one (you can see the page for the graph above here), but below I give a very basic overview for those who aren’t already familiar with NodeXL or network analysis graphs (disclosure: this group includes me, too).
What you’re looking at is a picture of the interrelationships between 177 individual Twitter users (or vertices) who used the #ASA2012 or #ASA12 hashtags, as captured via tweets that included either hashtag between 11:06 AM and 5:23 PM conference time on Saturday, 18 August (the second full day of the conference). Each green line (or edge) represents a “follow” relationship; a double-headed green line points to two people who follow each other, whereas a single-headed green line represents an unreciprocated follow relationship. The blue lines (also edges) represent either “mention” or “reply-to” relationships; the closed circles (or self-loop edges) represent tweets that didn’t mention or reply to any of the other 176 users on the graph. There are a couple areas where users seem to clump together, and these clumps are identified as groups (e.g., G1, G2, etc); these groups are sets of users who tend to interact with each other.
My first reactions when I saw this particular graph during ASA were as follows: first, I had agood laugh about the fact that “#digitaldualism” had, in 7th place, made the Top Hashtags list for the G2 group. Second, I was pleased to note that three Cyborgologists (plus friend of Cyborgology Alex Hanna) had together managed to occupy first through fourth place in the Top Replied-To list for the graph as a whole (which probably helps to explain the prominence #digitaldualism). In fact, Cyborgology’s fingerprints were all over this particular network graph, & I delighted in retweeting the link to it. What I didn’t notice until a few minutes later, however, was that the Top Replied-To list has a distinct gender skew: its members are two women and eight men.
To try and put this 20/80 split into context, let’s first compare the Top Replied-To list with the Top Mentioned list. A “mention” is when someone’s username appears in a tweet; this can happen in a reply, a retweet, a cc:, or just using someone’s username to talk about them. The Top Mentions list for the graph as a whole is much more gender-balanced, with four women, five men, and one user of unknown gender (@ASAnews). The Top Replied-To list, on the other hand, reflects not mentions but what happens in response to mentions; where the Top Mentions list shows who was talked about most, the Top Replied-To list shows who got responses from the people they talked about.
This graph shows 43 Twitter users who posted with the #CITASA hashtag, a group responsible for a disproportionate share of traffic on the #ASA2012 and #ASA12 hashtags.
So what’s going on with the gender difference (other than the fact that it’s there)?
The short answer is that we can’t come up with any solid guesses without doing a lot more data analysis. For example, we would have to look at all of the tweets in the sample to start proposing reasons why some of the 177 included users got responses while others didn’t, because we can’t know just from the picture how much garnering a reply has to do with who speaks versus to whom one speaks. To illustrate: when Nathan (@nathanjurgenson) and PJ (@pjrey) and I (@phenatypical) all attend the same session in-room and then argue about it on Twitter (which never happens…ok maybe that happens sometimes), we generate a lot of replies to each other. This increases the frequency that all three of us are “replied-to,” though it doesn’t necessarily mean that anyone beyond the three of us is listening (or cares about what we’re saying). Comparing the three of us to three hypothetical users who mostly ‘mention’ people more prestigious than they are, or people they don’t know, or people who don’t use the ASA hashtags, wouldn’t necessarily be a good comparison if we want to learn about gender and Twitter use at ASA in general.
If we were to find any gender effects on membership in the Top Replied-To group for this graph, we also wouldn’t know if those effects hold for the other 167 users in this sample; recall too that only people who used #ASA2012 or #ASA12 at least once during the specified timeframe are included in this group, so looking at ASA Twitter users in general may show different patterns as well. Marc also points out that, perhaps unsurprisingly, members of the ASA section on Communication and Information Technologies (#CITASA) provide a disproportionate amount of traffic on the ASA hashtags; a good analysis would have to take this into account, because findings more specific to CITASA members may not be generalizable even to tweeting ASA members in general. (You can download the data for the CITASA graph above here.) It would be useful to know the gender breakdown of all users who tweeted the #ASA2012 and #ASA12 hashtags anytime during the conference, as well as the gender breakdown for ASA attendees most generally, to make better comparisons.
All of that said, what’s your best guess? What behaviors, usage patterns, and attitudes might create a gender discrepancy in Top Replied-to, but not Top Mentioned? Can the graph be weighted differently to change this discrepancy, & what’s the significance of that? What kind of data analysis would you do to start getting at these questions?
I’m interested to hear what people think about this!
Whitney Erin Boesel (@phenatypical) is a woman who posts frequently in conference hashtag streams…and who’s still always surprised to discover people are listening.
As the 2012 meeting of the American Sociological Association (#ASA2012) kicks into gear, I want to use this post to start a conversation about a somewhat-contentious topic: academics’ use of Twitter, particularly at conferences. I begin by extending some of what’s already been written on Cyborgology about the use of Twitter at conferences, and then consider reasons why some people may find Twitter use off-putting or intimidating at conferences. I close by considering what Twitter users in particular can do to ease the “Twitter tensions” at ASA by being more inclusive. The stakes here include far more than just “niceness”; they include as well an opportunity to shape the shifting landscape of scholarly knowledge production.
Before I begin, I need to make two disclosures; I also want to define a few terms, so that the conversation that follows is more accessible to people who aren’t familiar with Twitter. Disclosure No. 1 is that this year will be my first time attending an ASA; at the time of writing, my impressions of the “Twitter tension” at ASA in particular are based on reports from friends and colleagues rather than on first-hand experience. Disclosure No. 2 is that, likemyCyborgologycolleagues, I’m a big fan of what we like to call augmented conferences, or conferences that make full use of Twitter and other digital media to enhance and expand conference participation both for those who can attend in person and for those who participate across geographic distance. (Readers who also see this type of model as the ideal conference may wish to skip the next two paragraphs, in which I explain some terminology relevant to backchannels and Twitter most generally.)
A backchannel from Theorizing the Web 2012, as seen from a mobile phone.
Augmented conferences frequently work to enhance participation through the use of backchannels, which are conversations about individual conference presentations or about the conference itself that take place in real-time through Twitter (and sometimes through other digital media). Threads of specific backchannel conversations are identified using hashtags, which are short bits of text with # in front of them (aka, #ASA2012). Hashtags are clickable links, and both Twitter users and non-users can follow a backchannel discussion by clicking on a hashtag or by entering the hashtag into the “search” field on Twitter; doing either will bring up all the tweets (or individual posts of 140 characters or less) that have that particular hashtag in them. The main hashtag for a big conference can become a bit chaotic, so presentation-specific backchannels are often marked with both the conference hashtag and a presentation-specific hashtag (you can see how this was done at Theorizing the Web 2012: in addition to the conference-specific hashtag #TtW12, each panel has its own specific hashtag listed in the program according to session number and room location).
So what’s a backchannel conversation like? Twitter users who are watching the presentation (either in the room or remotely, if the talk is livestreamed over the Internet) frequently quote or paraphrase the presenter’s points. A user who is live tweeting the presentation will attempt to transmit enough of the talk and following in-room discussion for someone who isn’t in the room (or watching online) to follow along; other users watching the presentation will tweet points they find particularly interesting, noteworthy, controversial, or enjoyable. Both users who are watching the presentation (in-room or via livestream) and those who are only following the backchannel will comment on and ask questions about points from the presentation.
Backchannel conversations often continue after a presentation ends, and if the presenter is a Twitter user as well, she’ll usually join in for a bit after her presentation is finished. A panel at an augmented conference may also have a backchannel moderator, whose job it is to live-tweet the presentations and to voice the best questions from the backchannel during in-room discussion; some intrepid speakers have also been known to field questions directly both from the room and from the backchannel simultaneously.
If you’ve never seen one happen, the truth is that a backchannel discussion is a pretty amazing thing. It allows people who can’t be physically present at a conference to participate, not just by making conference content available to them but by providing a way for them to add their voices to the discussions that take place as they are happening. Successful backchanneling also demands an intense engagement from in-room attendees, and therefore forces those who can be corporeally present to be intellectually present as well. One backchannel participant who clarifies a piece of presenter can improve the experience of attending a talk for unknown numbers of other participants, and a lively backchannel discussion can allow participants to identify key issues and questions before in-room discussion begins. All of these things help participants to make better use of limited in-room discussion time.
How *does* one approach stranger sociologists?
Backchannel discussions also allow conversation to continue after conference-weary bodies file out of stuffy conference rooms, or fly out from conference cities; some of us shy or introverted attendees may also find it easier to approach strangers in person after talking to them in a backchannel (just kidding—we all know there are no awkward sociologists). Backchanneling can therefore help to create and maintain the professional and personal relationships upon which survival in academia depend.
Perhaps most importantly, archived backchannel discussions represent an important form of conference proceedings, one that is more accessible by virtue of being both publically available online and (more often than not) written in the less “jargony” language that Twitter’s 140 character limit tends to demand. These versions of proceedings are accessible by availability and by design. When we take conference notes by live-tweeting instead of creating private digital or paper notes, we enact our commitment to reengaging academic sociology with the societies that surround it, to facilitating the spread of information, and to getting “out of the hotel conference room, and [into] the streets.” Participating in a backchannel is a political act, and in a certain sense, a backchannel discussion is a collective labor of love.
So now that ASA has wifi, why aren’t we all backchanneling? It turns out that not everyone thinks backchannels are so great. There’s been some friction at previous ASA meetings between attendees who use Twitter and attendees who don’t, and I think this is understandable. Even I admit that, in a way, Twitter can represent the worst of cultural speed-up. The expected response time on a critical tweet is a lot shorter than the expected response time on a critical journal article, and if one “follows” a good collection of people, Twitter can be an overwhelming assault of interesting ideas and articles, a personalized “data deluge.” Some presenters may be worried that wider, more rapid circulation of their unpublished work will lead not to increased opportunities for collaboration, but to getting “scooped”; others may fear discussing preliminary work they are not yet ready to commit to record. Given that the mantra is still “publish or perish,” the stakes can feel high.
There’s also the matter of presenting itself. In the age of Twitter, an anxious presenter must now worry not only about whether the computer users are taking notes or checking email, whether the notepad users are taking notes or doodling, and whether those people sitting quietly in the back row are actually sleeping, but also whether some of the audience is tweeting, and therefore not only ‘distracted’ but having a conversation of which the presenter herself is as-yet unaware. The presenter is, of course, always participating in the discussion; without her presentation, there would be no backchannel discussion at all! But we can acknowledge that presenting and backchanneling are different modes of participation, just as are presenting and attending, and that the difference between presenting and backchanneling in particular may be additionally disconcerting for speakers who are unfamiliar with Twitter and backchannels.
Taking notes? Or passing notes?
A non-user may feel as though a backchannel discussion of her presentation represents “passing notes during a talk, only if those notes were posted on a giant whiteboard behind the speaker so that everybody but her could read them.” Though a speaker can easily join the backchannel discussion following her presentation, she may in that moment want a drink or a nap (or both) far more than she wants to engage in digital discussion about her talk. Let’s admit, too, that it can be considerably more daunting (for user- and non-user presenters alike) to face a room that’s well prepared to ask critical questionsinstead of one that flounders for the first two-thirds of an in-room discussion period. Maybe this represents a drawbacks to moving past talks in which a speaker presents “to five bored attendees checking their email.”
Finally, given that new or unfamiliar technologies can irritating or intimidating in and of themselves, what percentage of ‘expert authorities’ want to risk losing face by fumbling with Twitter in front of some punkass hipster grad students? Though there are certainly some venerable figures who use and enjoy Twitter, perhaps it’s unsurprising that other academics with secure positions and established networks don’t see what bothering with Twitter would have to offer them. But why does any of this matter? Some of us love Twitter, some of us hate it, and some of us just don’t care; why is this worth writing a blog post about? Can’t the lovers love, and the haters hate, and all of us leave it at that?
In a word: No.
As DavidBanks (@DA_Banks), SarahWanenchak (@dynamicsymmetry), Nathan Jurgenson (@nathanjurgenson) & Pj Rey (@pjrey), and a number of others have argued, the old conference model needs to change, as do most of the models for how we academics circulate and disseminate information. Backchanneling represents one excellent way for academic conferences to take a step in the right direction, but at present those of us who feel that way are in the minority. Academia is notoriously slow to change, and “those entrenched in the old system, whose habits are better suited to yesteryear and who still have sufficient power to resist… any change” have little incentive to see the value that backchannels add to a conference. Therefore, I call for new tactics: I call for dialogue and outreach at ASA2012.
Make a new connection.
If you’re backchanneling this week, I challenge you to reach out to someone who isn’tbackchanneling. Consider offering to share your screen with someone for a talk. Show someone a backchannel conversation following a presentation, and explain how backchanneling works. See if you can’t help someone sign up for Twitter. Try to answer questions about what you’re doing and why you’re doing it with patience, compassion, and humor (even when those things aren’t extended to you, because at least once they probably won’t be). Try not to be too bitingly sarcastic on Twitter when you see a presentation you disagree with, and if you must break out the industrial strength snark, consider keeping it off the #ASA2012 hashtag. Don’t publically make fun of people who aren’t as tech-savvy as you are (even if you did think that whole ASA2012 “app” thing was really funny). Remember that there are understandable reasons some people are skeptical of backchanneling, and see if you can contribute—even just once—to making augmented conferences seem a little less alien, off-putting, or intimidating to someone who doesn’t yet see augmented conferences the way you do.
As academics, we need to work first and foremost on being more accessible to society; we also need to work on being more accessible to each other. Backchanneling can help us with the former, and it has certainly helped some of us with the latter, but we need to go further. How can we accomplish this? Let’s start the conversation.
Whitney Erin Boesel is on Twitter (@phenatypical), and is more than happy to help you get on Twitter, too!
White flight happens both online and offline. What is it with some white people?
Recently mentions of a new “real-time social feed” called App.net have been creeping into my Twitter feed. Just as the quietly simmering Diasporaand the running joke that is G+were geared to seize on collective Facebook malaise, it seems App.net is trying to seize on some degree of unrest among Twitter users before taking on Facebook as well. In this case, App.net promises that “users and developers [will] come first, not advertisers”; in an era of “if it’s free, you’re the product”—remember that the much love/hated Facebook “[is] free and always will be”—App.net proposes to offer a Twitter-like social feed (and eventually a “powerful ecosystem based on 3rd-party developer built ‘apps’”) on a paid membership basis instead.
At first, this struck me as a reasonable enough idea; I’m pretty much always willing to pay for the upgraded version of an app or service rather than be bombarded with ads (though in this case, my particular Twitter client and the AdBlock Plus add-on have already solved the problems of “promoted tweets” and Facebook ads). Yet it turns out App.net will not be an advertising- or promotion-free environment just because App.net itself won’t derive revenue from ads; the company has no plans to “restrict commercial messages from appearing on the service,” and instead suggests that users—who have “complete control over the kinds of messages they see”—simply unfollow accounts that post annoying messages. App.net describes this as “the beauty of a follow model,” but I’m skeptical; for instance, the “follow model” does not seem to have stopped spammers on Twitter, and unlike App.net’s founder Dalton Caldwell, I’m not convinced a $50 pay wall will keep spammers away. Still, I liked the idea of my information (“my information”) not being sold to marketers, so I kept reading.
When I got to the $50 price point (pre-paid) of joining App.net for a year, however, I started to see the service a bit differently. I realize that any app or service charging at least $4.17 per month (and there are a lot of them) also costs at least $50 per year, but that actually isn’t the point here; the point is the stratifying effect of asking for $50 upfront instead of asking for $4.17 every month. Was this stratifying effect intentional, or an oversight? Some clicking around indicates that it’s probably intentional, with one interview article stating that the $50 pre-paid membership cost is “really more of a ‘are you serious’ fee.” Caldwell believes that “Twitter could have been something more, and perhaps better, than what it has become,” and so has set out to build a service not for the masses, “but for the hacker masses.”
Newsflash: People of Color use Twitter!
The “hacker masses” are, of course, a much less diverse crowd than are the ‘regular’ masses. Recall that Twitter’s original ‘early adopter’ user base in 2007 was the so-called digerati, who are largely affluent white men with connections to the tech industry; recall as well that in 2012, “it’s a black Twitterverse; white people only live in it.” “How Black People Use Twitter” got a lot of attention on Slate.com two years ago (despite describing how only some Black users use Twitter), and let’s not forget how many Arab-region users joined Twitter during last year’s Arab Spring. Meanwhile, those “keen and savvy” early adopters now complain because services like Twitter and Facebook “haven’t developed with us” [emphasis in original], and Caldwell himself sees K-Mart ads in his feed as just another sign of Twitter’s appalling degradation and debasement. OMG it’s the end of the world: K-mart shoppers and people of color found Twitter.
Uh-oh, Grandma’s on Facebook.
I’m now wondering if App.net doesn’t mark the beginning of “white flight” from Twitter and Facebook, just as danah boyd (@zephoria) has argued that Facebook was the “white flight” from Myspace before that. Both sites have certainly grown beyond their early-adopter user bases: Twitter had 500 million users as of February 2012, and with 955 million users [pdf] as of June 2012, “everyone” is supposedly on Facebook; your momis onFacebook(hell, my mom’s on Twitter, too), and there’s even a growing chanceyour grandma is on Facebook (though I admit that mine isn’t). Facebook has become so quotidian—some would even say pedestrian—that as Laura Portwood-Stacer (@lportwoodstacer) argues, not being on Facebook has become the new, cool status marker (esp for affluent white tech people). Given all the cultural and economic capital there is to be gained from participating in social media, however, it wouldn’t be surprising if some people who are ‘too cool’ for Facebook and Twitter are not yet too cool for social networking sites in general, especially sites you need $50, $100, or $1000 upfront to join. In fact, App.net is betting there are at least 10,000 people willing to pay $50, to start.
Before I return to the issue of App.net’s $50 entry-level membership fee and its stratifying effects, I want to acknowledge that, although race and class are complexly interrelated and intersectingaxes of oppression, they are not the same thing. One of my pet peeves is when people treat race and class as if they’re interchangeable; for instance, when the Fordham Institute talks about the 25 “fastest-gentrifying neighborhoods” in America, the author is really referencing US Census data for the 25 zip codes with the largest increases in percentages of white residents. As a transitive verb, “gentrified” means “renovated and improved so that it conforms to middle-class taste”; Fordham is therefore using ‘percentage of white residents’ as a proxy for ‘percentage of middle-class residents’, which inherently perpetuates the stereotypes that white people are middle-class and people of color are poor. Because of this, I find Fordham’s proxy (and others like it) to be ideologically problematic, even if an influx of white people does seem to correlate with fewer bodegas and more cupcake merchants. Plus, when we remember that the adjective meaning of “gentrified” is “more refined or dignified,” equating ‘more white’ with ‘more gentrified’ is just offensive.
The Mission, San Francisco: home to both gang violence and gourmet cupcakes.
Anyway, the point here is that when I talk about a possible link between App.net’s class-stratifying $50 backing fee and the beginning of ‘white flight’ from Facebook, I’m not suggesting a 1:1 correlation between whiteness and affluence, nor am I suggesting that race and class are interchangeable. I am, however, referencing the fondness that some affluent white people have for buying goods and services that help them decrease the visibility of poor people and people of color around them.
If the ‘white flight’ from Myspace to Facebook was like the post-war migration of white people from urban areas to tract houses in the suburbs, App.net could represent the digital equivalent of white people moving from suburban tract houses to gated communities or urban loft conversions. It contains elements of both white flight (affluent white people distancing themselves from the more diverse user bases of Facebook and Twitter) and gentrification (affluent white people creating a site that conforms to their tastes and has a higher cost of entry), and to me, these things make App.net seem a lot less appealing: I’m happy to escape “being the product,” but joining a digital country club holds little appeal.
In addition to market appeal based subtly and not-so-subtly on fleeing from the ‘Others,’ and on utopian rhetoric about fleeing from evil corporations (“Open. Free. Joy. Wonder. Peace. Perfection”), App.net taps into the same neoliberal self-interest on which all privatization ventures depend. Much of the enthusiasm I’ve seen in my own Twitter feed has been from people who are angry about being “the product,” but if there’s a harm to being the product (such that would motivate those who can pay to join a different social networking site to do so), shouldn’t we maybe address that harm directly and collectively?
Ah, the suburbs.
Buying our way out of personal exposure to a problem doesn’t address the problem itself, and it still leaves those who can’t afford to buy their way out exposed. Buying bottled watermight get your kid away from (say) trichloroethylene, but it won’t stop your neighborhood from becoming a leukemia cluster; ‘voting with your dollar’ for App.net instead of Facebook or Twitter might subject you to fewer ads and less data-mining, but it’s not going to affect how Facebook, Google, or anyone else operates, nor will it slow the push toward targeted marketing in general.
One might be tempted to argue that ‘early adopters’ in general tend to be disproportionately white, male, and economically privileged, and that perhaps App.net would—like both Myspace and Facebook—become more diverse over time (especially if the price-point of using their service came down). I tend to think not, given that the ‘for us, by us’ here is software developers. Or perhaps we shouldn’t expect App.net to have any kind of positive impact on the world; maybe they’re just out to make some money by offering a service for which there seems to be a market. But for those of us who see the appeal or value of a user-centered social networking site, I wonder if this is the best way to go about building one.
Last spring at TtW2012, a panel titled “Logging off and Disconnection” considered how and why some people choose to restrict (or even terminate) their participation in digital social life—and in doing so raised the question, is it truly possible to log off? Taken together, the four talks by Jenny Davis (@Jup83), Jessica Roberts (@jessyrob), Laura Portwood-Stacer (@lportwoodstacer), and Jessica Vitak (@jvitak) suggested that, while most people express some degree of ambivalence about social media and other digital social technologies, the majority of digital social technology users find the burdens and anxieties of participating in digital social life to be vastly preferable to the burdens and anxieties that accompany not participating. The implied answer is therefore NO: though whether to use social media and digital social technologies remains a choice (in theory), the choice not to use these technologies is no longer a practicable option for number of people.
In this essay, I first extend the “logging off” argument by considering that it may be technically impossible for anyone, even social media rejecters and abstainers, to disconnect completely from social media and other digital social technologies (to which I will refer throughout simply as ‘digital social technologies’). Consequently, decisions about our presence and participation in digital social life are made not only by us, but also by an expanding network of others. I then examine two prevailing privacy discourses—one championed by journalists and bloggers, the other championed by digital technology companies—to show that, although our connections to digital social technology are out of our hands, we still conceptualize privacy as a matter of individual choice and control. Clinging to the myth of individual autonomy, however, leads us to think about privacy in ways that mask both structural inequality and larger issues of power. Finally, I argue that the reality of inescapable connection and the impossible demands of prevailing privacy discourses have together resulted in what I term documentary consciousness, or the abstracted and internalized reproduction of others’ documentary vision. Documentary consciousness demands impossible disciplinary projects, and as such brings with it a gnawing disquietude; it is not uniformly distributed, but rests most heavily on those for whom (in the words of Foucault) “visibility is a trap.” I close by calling for new ways of thinking about both privacy and autonomy that more accurately reflect the ways power and identity intersect in augmented societies.
We’re always connected, whether we’re connecting or not.
For the skeptical reader in particular, I want to begin by highlighting that the effects of neither participation nor non-participation in digital sociality are uniform or determined, and that both are likely to vary considerably across different social positions and contexts. An illustrative (if somewhat extreme) example is the elderly: Alexandra Samuels caricatures the absurdity of fretting over seniors who refuse online engagement, and my own socially active but offline-only grandmother makes a great case study in successful living without digital social technology. Though 84 years old, my grandmother is healthy and can get around independently; she lives in a seniors-only community of a few thousand adults (nearly all of whom are offline-only as well), and a number of her neighbors have become her good friends. She has several children, grandchildren, and great-grandchildren who live less than an hour away, and who call and visit regularly. As a financially stable retiree, she can say with confidence that there will be no job-hunting in her future; her surviving siblings still send letters, and her adult children print out digital family photos to show her. For these reasons and others, it would be hard to make the case that either she or any one of her similarly situated friends suffers from digital deprivation.
In contrast, the “Logging Off and Disconnection” panel highlights how the picture of offline-only living shifts if some of the other factors I list above change. Whereas my grandmother has a number of friends with whom she spends time (and who, like her, do not use digital social technologies), Davis describes the isolation that digital abstainers experience when many of the friends with whom they spend time do use digital social technologies. Much to their dismay, non-participating friends of social media enthusiasts in particular can find themselves excluded from both offline and online interaction within their own social groups. Similarly, Roberts finds that even 24 hours of “logging off” can be impossible for students if their close friends, family members, or significant others expect them to be constantly (digitally) available. In these contexts, it becomes difficult to refuse digital engagement without seeming also to refuse obligations of care.
Nor is what I will call abstention-related atrophy limited to relationships with friends and family members; professional relationships and even career trajectories can suffer as well. Vitak points out that, for job-seekers, the much-maligned proliferation of ‘weak ties’ that social media has been accused of fostering is a greater asset for gaining employment than is a smaller assortment of ‘strong ties.’ Modern life has become sufficiently saturated with social media to support use of what Portwood-Stacer calls its “conspicuous non-consumption” as a status marker: in the United States, where 96.7 percent of households have at least one television, “I’m not on Facebook” is the new “I don’t even own a TV.” That even a few people read the purposeful rejection of social media as a privilege signifier implicitly demonstrates the high cost of abstaining from social media.
You can opt-out, but you can’t make your friends opt-out.
Conversations about logging off or disconnecting have continued in the weeks since TtW2012. Most recently, PJ Rey (@pjrey) makes the case that social media is a non-optional system; because societies and technologies are always informing and affecting each other, “we can’t escape social media any more than we can escape society itself.” This means that the extent to which we can opt-out is limited; we can choose not to use Facebook, for example, but we can no longer choose to live in a world in which no one else uses Facebook (whether for planning parties or organizing protests). As does Davis, Rey argues that “conscientious objectors of the digital age” therefore risk losing social capital in a number of ways.
I would like to suggest, however, that even those who are “secure enough” to quit social media and other digital social technologies can not separate from them fully, nor can so-called “Facebook virgins” remain pure abstainers. Rejecters and abstainers continue to live within the same socio-technical system as adopters and everyone else, and therefore continue to affect and to be affected by digital social technology indirectly; they also continue to leave digital traces through the actions of other people. As I elaborate below, not connecting and not being connected are two very different things; we are always connected to digital social technologies, whether we are connecting to them or not. A number of digital social technology companies capitalize on this fact, and in so doing amplify the extent to which digital agency is increasingly distributed rather than individualized.
Below, I use Facebook as a familiar example to illustrate the near-impossibility of erasing digital traces of one’s self most generally. Many of the surveillance practices that follow here are not unique to Facebook, but the difficulty of achieving a full disengagement from Facebook can serve as an indicator of how much more difficult a full disengagement from all digital social technology would be. First, consider some of the issues that face people who actually have Facebook accounts (at minimum a username and password). Facebook has tracked its users’ web behavior even when they are logged out of Facebook; the “fixed” version of the site’s cookies still track potentially identifying information after users log out, and these same cookies are deployed whenever anyone (even a non-user) views a Facebook page. Last year, a 24-year-old law student named Max Schrems discovered that Facebook retains a wide array of user profile data that users themselves have deleted; Schrems subsequently launched 22 unique complaints, started an initiative called Europe vs. Facebook, and earned Facebook’s Ireland offices an audit.
Are you my shadow profile?
In one particular complaint, Schrems alleges that Facebook not only retains data it should have deleted, but also builds “shadow profiles” of both users and non-users. These shadow profiles contain information that the profiled individuals themselves did not choose to share with Facebook. For a Facebook user, a shadow profile could include information about any pages she has viewed that have “Like” buttons on them, whether she has ever “Liked” anything or not. User and non-user shadow profiles alike contain what I call second-hand data, or information obtained about individuals through other individuals’ interactions with an app or website. Facebook harvests second-hand data about users’ friends, acquaintances, and associates when users synchronize their phones with Facebook, import their contact lists from other email or messaging accounts, or simply search Facebook for individual names or email addresses. In each case, Facebook acquires and curates information that pertains to individuals other than those from whom the information is obtained.
Second-hand data collection on and through Facebook is not limited to the creation of shadow profiles, however. As a recent article elaborated, Facebook’s current photo tagging system enables and encourages users to disclose a wealth of information not only about themselves, but also about the people they tag in posted photos. (Though not mentioned in the piece, the “tag suggestions” provided by Facebook’s facial recognition software have made photo tagging nearly effortless for users who post photos, while removing tags now involves a cumbersome five-click process per each tag that a pictured user wants removed.) Recall, too, that other companies collect second-hand data through Facebook each time a Facebook user authorizes a third party app; by default, the third-party app can ‘see’ everything the user who authorized it can see, on each of that user’s friends’ profiles (the same holds true for games and for websites that allow users to log-in with their Facebook accounts).
Those users who dig through Facebook’s privacy settings can prevent apps from accessing some of their information by repeating the tedious, time-consuming process required to block a specific app for each and every app that any one of their Facebook ‘friends’ might have authorized (though the irritation-price of doing so clearly aims to guide users away from this sort of behavior). Certain pieces of information, however—a user’s name, profile picture, gender, network memberships, username, user id, and ‘friends’ list—remain accessible to Facebook apps, no matter what; Facebook states that this makes one’s friends’ experiences on the site (if not one’s own) “better and more social.” Users do have the ‘nuclear option’ of turning off all apps, though this action means they cannot use apps themselves; their information also still remains available for collection through their friends’ other Facebook-related activities.
Facebook representatives have denied any wrongdoing, denied the existence of shadow profiles per se (though a former Facebook employee recently confirmed that the company builds “dark profiles” of non-users), and maintained that there is nothing non-standard about the company’s data collection practices. Nonetheless, even the possibility of shadow profiles raises a complicated question about where to draw the line between information that individuals ‘choose willingly’ to share (and are therefore responsible for assuming it will end up on the Internet), and “information that accumulates simply by existing.” The difficulty of making this determination reflects not only the tensions between prevailing privacy discourses, but also the growing ruptures between the ways in which we conceptualize privacy and the increasingly augmented world in which we live.
Your privacy is your friends’ privacy–and vice versa.
As a headline in The Atlantic put it recently, “On Facebook, Your Privacy is Your Friends’ Privacy”—but what does that mean? How should we weigh which of our friends’ desires against which of our own? How are we to anticipate the choices our friends might make, and on whom does the responsibility fall to choose correctly? The problem is that we tend to think of privacy as a matter of individual control and concern, even though privacy—however we define it—is now (and has always been) both enhanced and eroded by networks of others. In a society that places so much emphasis on radical individualism, we are ill-prepared to grapple with the rippling and often unintended consequences that our actions can have for others; we are similarly disinclined to look beyond the level of individual actions in asking why such consequences play out in the ways that they do.
‘Simply existing’ does generate more information than it did two generations ago, in part because so many different corporations and institutions are attempting to capitalize on the potentials for targeted data collection afforded by a growing number of digital technologies. At the same time, surveillance of individual behavior for commercial purposes is nothing new, and Facebook is hardlythe only companybuildingdata profiles to which the profiled individuals themselves have incomplete access (if any access at all). What is comparatively new about Facebook-style surveillance in social media is the degree to which disclosure of our personal information has become a product not only of choices we make (knowingly or unknowingly), but also of choices made by our family members, friends, acquaintances, or professional contacts.
Put less eloquently: if Facebook were an STI, it would be one that you contract whenever any of your old classmates have unprotected sex. Even one’s own abstinence is no longer effective protection against catching another so-called ‘data double’ or “data self,” yet we still think about privacy and disclosure as matters of individual choice and responsibility. If your desire is to disconnect completely, the onus is on you to keep any and all information about yourself—even your name—from anyone who uses Facebook, or who might use anything like Facebook in the future.
If we dispense with digital dualism—the idea that the ‘virtual,’ ‘digital,’ or ‘online’ world is somehow separate and distinct from the ‘real,’ ‘physical,’ or ‘face to face’ world—it becomes apparent that not connecting to digital social technologies and not being connected to digital social technologies are two different things. Whether as a show of conspicuous non-consumption, an act of atonement and catharsis (as portrayed in Kelsey Brannan’s [@KelsBran] film Over & Out), or for other reasons entirely, we can choose to accept the social risks of deleting our social media profiles, dispensing with our gadgetry, and no longer connecting to others through digital means.
Yet whether we feel liberated, isolated, or smugly self-satisfied in doing so, we have not exited the ‘virtual world’; we remain situated within the same augmented reality, connected to each other and to the only world available through flows that are both physical and digital. I email photographs, my mother prints them out, and my grandmother hangs them in frames on her wall; a social media refuser meets her own searchable reflection in traces of book reviews, grant awards, department listings, and RateMyProfessors.com; a nearby friend sees you check-in early at your office, and drops by to surprise you with much needed coffee. A news story is broken and researched via Twitter, circulated in a newspaper, amplified by a TV documentary, and referenced in a book that someone writes about on a blog. Whether the interface at which we connect is screen, skin, or something else, the digital and physical spaces in which we live are always already enmeshed. Ceasing to connect at one particular type of interface does not change this.
Even Houdini can’t escape digital social technology.
In stating that connection is inescapable, I do not mean to suggest that all patterns of connection are equitable or equivalent in form, function, or impact. Connection does not operate independent of variables such as race, class, gender, ability, or sexual orientation; digital augmentation is not a panacea for oppression, and neither has nor will magically eliminate social and structural inequality to birth a technoutopian future. My intent here in focusing on broader themes is not to diminish the importance of these differences, but to highlight three key points about digital social technology in an augmented world:
1.) First, our individual choices to use or reject particular digital social technologies are structured not only by cultural, economic, and technological factors, but also by our social, emotional, and professional ties to other people;
2.) Second, regardless of how much or how little we choose to use digital social technology, there are more digital traces of us than we are able to access or to remove;
3.) Third, even if we choose not to participate in digital social life ourselves, the participation of people we know still leaves digital traces of us. We are always connected to digital social technologies, whether we are connecting through them or not.
So far I’ve argued that whether we leave digital traces is not a decision we can make autonomously, because our friends, acquaintances, and contacts also make these decisions for us. These traces are largely unavoidable, as we cannot escape being connected to digital social technologies anymore than we can escape society itself. But do our current notions of privacy reflect this fact? I now consider two different privacy discourses to show that 1) although our connections to digital social technology are out of our hands, we still conceptualize privacy as a matter of individual choice and control, and 2) clinging to the myth of individual autonomy leads us to think about privacy in ways that mask both structural inequality and larger issues of power.
Your privacy is out of your hands, but protecting it is still your responsibility.
Inescapable connection notwithstanding, we still largely conceptualize disclosure as an individual choice, and privacy as a personal responsibility. This is particularly unsurprising in the United States, where an obsession with self-determination is foundational not only to the radical individualism that increasingly characterizes American culture, but also to much of our national mythology (to let go of the ‘autonomous individual’ would be to relinquish the “bootstrap” narrative, the mirage of meritocracy, and the shaky belief that bad things don’t happen to good people, among other things).
Though the intersection of digital interaction and personal information is hardly localized to the United States, major digital social technology companies such as Facebook and Google are headquartered in the U.S.; perhaps relatedly, the two primary discourses of privacy within that intersection share a good deal of underlying ideology with U.S. national mythology. The first of these discourses centers on a paradigm that I’ll call Shame On You, and spotlights issues of privacy and agency; the second centers on a paradigm that I’ll call Look At Me, and spotlights issues of privacy and identity.
Blaming the victim.
“You shouldn’t have put it on the Internet, stupid!” Within the Shame On You paradigm, the control of personal information and the protection of personal privacy are not just individual responsibilities, but also moral obligations. Choosing to disclose is at best a risk and a liability; at worst, it is the moment we bring upon ourselves any unwanted social, emotional, or economic impacts that will stem (at any point, and in any way) from either an intended or an unintended audience’s access to something we have made digitally available. Disclosure is framed as an individual choice, though we need not choose intentionally or even knowingly; it can be the choice to disclose information, the choice to make incorrect assumptions about to whom information is (or will be) accessible, or the choice to remain ignorant of what, when, by whom, how, and to what end that information can be made accessible.
A privacy violation is therefore ultimately a failure of vigilance, a failure of prescience; it redefines as disclosure the instant in which we should have known better, regardless of what it is we should have known. Accordingly, the greatest shame in compromised privacy is not what is exposed, but the fact of exposure itself. We judge people less for showing women their genitals, and more for being reckless enough to get caughtdoing so on Twitter.
Shame On You was showcased most recently in the commentary surrounding the controversial iPhone app “Girls Around Me,” which used a combination of public Google Maps data, public Foursquare check-ins, and ‘publicly available’[i] Facebook information to create a display of nearby women. The creators of Girls Around Me claimed their so-called “creepy” app was being targeted as a scapegoat, and insisted that the app could just as well be used to locate men instead of women. Nonetheless, the creators’ use of the diminutive term “girls” rather than the more accurate term “women” exemplifies the sexism and the objectification of women on which the app was designed to capitalize. (If the app’s graphic design somehow failed to make this clear, see also one developer’s comments about using Girls Around Me to “[avoid] ugly women on a night out”).
The telling use of “girls” seemed to pass uncommented upon, however, and most accounts of the controversy (with fewexceptions) omitted gender and power dynamics from the discussion—as well as “society, norms, politics, values and everything else confusing about the analogue world.” The result was a powerful but unexamined synergy between Shame On You and the politics of sex and visibility, one that cast as transgressors women who had dared not only to go out in public, but to publicly declare where they had gone.
Another blogger admonishes that, “the only way to really stay off the grid is to never sign up for these services in the first place. Failing that, you really should take your online privacy seriously. After all, Facebook isn’t going to help you, as the more you share, the more valuable you are to its real customers, the advertisers. You really need to take responsibility for yourself.” Still another argues that conventional standards of morality and behavior no longer apply to digitally mediated actions, because “publishing anything publicly online means you have, in fact, opted in”—to any and every conceivable (or inconceivable) use of whatever one might have made available. The pervasive tone of moral superiority, both in these articles and in others like them, proclaims loudly and clearly: Shame On You—for being foolish, ignorant, careless, naïve, or (worst of all) deliberately choosing to put yourself on digital display.
Sexism: still alive and well.
Accounts such as these serve not only to deflect attention away from problems like sexism and objectification, but to normalize and naturalize a veritable litany of questionable phenomena: pervasive surveillance, predatory data collection, targeted ads, deliberately obtuse privacy policies, onerous opt-out procedures, neoliberal self-interest, the expanding power of social media companies, the repackaging of users as products, and the simultaneous monetization and commoditization of information, to name just a few. These accounts perpetuate the myth that we are all autonomous individuals, isolated and distinct, endowed with indomitable agency and afforded infinite arrays of choices.
With other variables obfuscated or reduced to the background noise of normalcy, the only things left to blame for unanticipated or unwanted outcomes–or for our disquietude at observing such outcomes–are those individuals who choose to expose themselves in the first place. Of course corporations try to coerce us into “putting out” information, and of course they will take anything they can get if we are not careful; this is just their nature. It is up to us to be good users, to keep telling them no, to remain vigilant and distrustful (even if we like them), and never to let them go all the way. We are to keep the aspirin between our knees, and our data to ourselves.
Shame On You extends beyond disclosure to corporations, and—for all its implicit digital dualism—beyond digitally mediated disclosure as well. Case in point: during the course of writing this essay, I received a mass-emailed “Community Alert Bulletin” in which the Chief of Police at my university campus warned of “suspicious activity.” On several occasions, it seems, two men have been seen “roaming the library;” one of them typically “acts as a look out,” while the other approaches a woman who is sitting or studying by herself. What does one man do while the other keeps watch? He “engages” the woman, and “asks for personal information.” The “exact intent or motives of the subjects” is unknown, but the ‘Safety Reminders’ at the end of the message instruct, “Never provide personal information to anyone you do not know or trust.”
Who escapes blame when we blame the victim?
If ill-advised disclosure were always this simple—suspicious people asking us outright to reveal information about ourselves—perhaps the moral mandate of Shame On You would seem slightly less ridiculous. As it stands, holding individuals primarily responsible for violations of their own privacy expands the operative definition of “disclosure” to absurd extremes. If we post potentially discrediting photos of ourselves, we are guilty of disclosure through posting; if friends (or former lovers) post discrediting photos of us, we are guilty of disclosure through allowing ourselves to be photographed; if we did not know that we were being photographed, we are guilty of disclosure through our failure to assume that we would be photographed and to alter our actions accordingly. If we do not want Facebook to have our names or our phone numbers, we should terminate our friendships with Facebook users, forcibly erase our contact information from those users’ phones, and thereafter give false information to any suspected Facebook users we might encounter. This is untenable, to say the least. The inescapable connection of life in an augmented world means that exclusive control of our personal information, as well as full protection of our personal privacy, is quite simply out of our personal hands.
* * * * *
This couple has “nothing to hide.”
The second paradigm, Look At Me, at first seems to represent a competing discourse. Its most vocal proponents are executives at social- and other digital media companies, along with assorted technologists and other Silicon Valley ‘digerati’. This paradigm looks at you askance not for putting information on the Internet, but for forgetting that “information wants to be free”—because within this paradigm, disclosure is the new moral imperative. Disclosure is no longer an action that disrupts the guarded default state, but the default state itself; it is not something one chooses or does, but something one is, something one has always-already done. Privacy, on the other hand, is a homespun relic of a bygone era, as droll as notions of a flat earth; it is particularly impractical in the 21st century. After all, who really owns a friendship? “Who owns your face if you go out in public?”
Called both “openness” and “radical transparency,” disclosure-by-default is touted as a social and political panacea; it will promote kindness and tolerance toward others, fuel progress and innovation, create accountability, and bring everyone closer to a better world. Alternatively, clinging to privacy will merely harbor evil people and condemn us to “generic relationships.” The enlightened “don’t believe that privacy is a real issue,” and anyone who maintains otherwise is suspect; as even WikiLeaks activist Jacob Appelbaum (@ioerror) has lamented, privacy is cast “as something that only criminals would want.” Our greatest failings are no longer what do or what we choose, but who we are; our greatest shame is not in exposure, but in having or being something to hide.
if you have nothing to hide, you have nothing to fear…right?
“Transparency,” too, has been popularized into a buzzword (try web-searching “greater transparency,” with quotes). In an age of what Jurgenson and Rey (@nathanjurgenson and @pjrey) have called liquid politics, people demand transparency from institutions in the hope that exposure will encourage the powerful to be honest; in return, institutions offer cryptic policy documents, unreadable reports, and “rabbit hole[s] of links” as transparency simulacra. Yet we continue to push for transparency from corporations and governments alike, which suggests that, to some degree, we do believe in transparency as a means to progressive ends. Perhaps it is not such a stretch, then, for social media companies (and others) to ask that we accept radical transparency for ourselves as well?
G+ was supposed to be the Anti-Facebook…or was it?
The 2011 launch of social network-cum-“identity service” Google+ served to test this theory, but the protracted “#nymwars” controversy that followed seemed not to be the result that Google had anticipated. Although G+ had been positioned as ‘the anti-Facebook’ in advance of its highly anticipated beta launch, within four weeks of going live Google decided not only to enforce a strict ‘real names only’ policy, but to do so through a “massive deletion spree” that quickly grew into a public relations debacle. The mantra in Silicon Valley is, “Google doesn’t get social,” and this time Google managed to (as one blogger put it) “out-zuck the Zuck.” Though sparked by G+, #nymwars did not remain confined to G+ in its scope; nor were olderbattlelinesaroundprivacy and anonymity redrawn for this particular occasion.
On one side of the conflagration, rival data giants Google and Facebook both pushed their versions of ‘personal radical transparency’; they were more-or-less supported by a loose assortment of individuals who either had “nothing to hide,” or who preached the fallacy that, ‘if you have nothing to hide, you have nothing to fear.’ The ‘nothing to hide’ argument in particular has been a perennial favorite for Google; well before the advent of G+ and #nymwars, CEO Eric Schmidt rebuked, “If you have something that you don’t want anyone to know, maybe you shouldn’t be doing it in the first place.” Unsurprisingly, Schmidt’s dismissive response to G+ users with privacy concerns was a smug, “G+ is completely optional. No one is forcing you use it.” If G+ is supposed to be an ‘identity service,’ it seems only some identities are worthy of being served.
Issues of power are conspicuously absent from Look At Me, and Google makes use of this fact to gloss the profound difference between individuals pressuring a company to be transparent and a company pressuring (or forcing) individuals to be transparent. Google is transparent, for example, in its ad targeting, but allowing users either to opt-out of targeted advertising or to edit the information used in targeting them does not change the fact that Google users are being tracked, and that information about them is being collected. This kind of ‘transparency’ offers users not empowerment, but what Davis (@Jup83) calls “selective visibility”: users can reduce their awareness of being tracked by Google, but can do little (short of complete Google abstention) to stop the tracking itself.
Transparency can be a real drag.
Such ‘transparency’ therefore has little effect on Google in practice; with plenty more fish in the sea (and hundreds of millions of userfish already in its nets), Google has little incentive to care whether any particular user does or does not continue to use Google products. Individual users, on the other hand, can find quitting Google to be a right pain, and this imbalance in the Google/user relationship effectively gives carte blanche to Google policymakers. This is especially problematic with respect to transparency, which has a far greater impact on individual Google users than it does on Google itself.
Google may have ‘corporate personhood’, but persons have identities; in the present moment, many identities still serve to mark people for discrimination, oppression, and persecution, whether they are “evil” or not. Look At Me claims personal radical transparency will solve these problems, yet social media spaces are neither digital utopias nor separate worlds; all regular “*-isms” still apply, and real names don’t stop bullies or trolls in digital spaces any more than they do in conventional spaces. At the height of irony, even ‘real-named’ G+ users who supported Google’s policy still trolled other users who supported pseudonyms.
boyd offers a different assessment of ‘real names’ policies, one that stands in stark contrast to the doctrine of radical transparency. She argues that, far from being empowering, ‘real name’ policies are “an authoritarian assertion of power over vulnerable people.” Geek Feminism hosts an exhaustive list of the many groups and individuals who can be vulnerable in this way, and Audrey Watters (@audreywatters) explains that many people in positions of power do not hesitate to translate their disapproval of even ordinary activities into adverse hiring and firing decisions. Though tech CEOs call for radical transparency, a senior faculty member (for example) condemns would-be junior faculty whose annoying “quirks” turn up online instead of remaining “stifle[d]” and “hidden” during the interview process. As employers begin not only to Google-search job applicants, but also to demand Facebook passwords, belonging to what Erving Goffman calls a “discreditable group” carries not just social but economic consequences.
Transparency can be a weapon. Who’s pointing it at whom?
Rey points out that there are big differences between cyber-libertarianism and cyber-anarchism; if “information” does, in fact, “want to be free,” it does not always “want” to be free for the same reasons. ‘Openness’ does not neutralize preexisting inequality (as the Open Source movement itself demonstrates), whereas forced transparency can be a form of outing with dubious efficacy for encouraging either tolerance or accountability. As boyd, Watters, and Geek Feminism demonstrate, those who call most loudly for radical transparency are neither those who will supposedly receive the greatest benefit from it, nor those who will pay its greatest price. Though some (economically secure, middle-aged, heterosexual, able-bodied) white men acknowledged their privilege and tried to educate others like them about why pseudonyms are important, the loudest calls for ‘real names’ were ultimately the “most privileged and powerful” calling for the increased exposure of marginalized others. Maybe the full realization of an egalitarian utopia would lead more people to choose ‘openness’ or ‘transparency’, or maybe it wouldn’t. But strong-arming more people into ‘openness’ or ‘transparency’ certainly will not lead to an egalitarian utopia; it will only exacerbate existing oppressions.
The #nymwars arguments about ‘personal radical transparency’ reveal that Shame On You and Look At Me are at least as complementary as they are competing. Both preach in the same superior, moralizing tone, even as one lectures about reckless disclosure and the other levels accusations of suspicious concealment. Both would agree to place all blame squarely on the shoulders of individual users, if only they could agree on what is blameworthy. Both serve to naturalize and to normalize the same set of problematic practices, from pervasive surveillance to the commoditization of information.
Most importantly, both turn a blind eye to issues of inequality, identity, and power, and in so doing gloss distinctions that are of critical importance. If these two discourses are as much in cahoots as they are in conflict, what is the composite picture of how we think about privacy, choice, and disclosure? What is the impact of most social media users embracing one paradigm, and most social media designers embracing the other?
Documentary consciousness entails the ever-present sense of a looming future failure.
I now consider one of the many impacts that follow from being inescapably connected in a society that still masks issues of power and inequality through conceptualizations of ‘privacy’ as an individual choice. I argue that the reality of inescapable connection and the impossible demands of prevailing privacy discourses have together resulted in what I term documentary consciousness, or the abstracted and internalized reproduction of others’ documentary vision. Documentary consciousness demands impossible disciplinary projects, and as such brings with it a gnawing disquietude; it is not uniformly distributed, but rests most heavily on those for whom (in the words of Foucault) “visibility is a trap.” I close by calling for new ways of thinking about both privacy and autonomy that more accurately reflect the ways power and identity intersect in augmented societies.
Always maybe watching.
Just before the turn of the 19th century, Jeremy Bentham designed a prison he called the Panopticon. The idea behind the prison’s circular structure was simple: a guard in a central tower could see into any of the prisoners’ cells at any given time, but no prisoner could ever see into the tower. The prisoners would therefore be subordinated by this asymmetrical gaze: because they would always know that they could be watched, but would never know if they werebeing watched, the prisoners would be forced to act at all times as if they were being watched, whether they were being watched or not. In contemporary parlance, Bentham’s Panopticon basically sought to crowd-source the labor of monitoring prisoners to the prisoners themselves.
Though Bentham’s Panopticon itself was never built, Michel Foucault used Bentham’s design to build his own concept of panopticism. For Foucault, the Panopticon represents not power wielded by particular individuals through brute force, but power abstracted to the subtle and ideal form of a power relation. The Panopticon itself is a mechanism not just of power, but of disciplinary power; this kind of power works in prisons, in other types of institutions, and in modern societies generally because citizens and prisoners alike, aware at all times that they could be under surveillance, internalize the panoptic gaze and reproduce the watcher/watched relation within themselves by closely monitoring and controlling their own conduct. Discipline (and other technologies of power) therefore produce docile bodies, as individuals self-regulate by acting on their own minds, bodies, and conduct through technologies of the self.
Foucault famously held that “visibility is a trap”; were he alive today, it is unlikely Foucault would be on board with radical transparency. Accordingly, it has become well-worn analytic territory to critique social media and digital social technologies by linking to Foucault’s panoptic surveillance. As early as 1990, Mark Poster argued that databases of digitalized information constituted what he termed the “Superpanopticon.” Since then, others have pointed out that “[even] minutiae can create the Superpanopticon”—and it would be difficult to argue that social media websites don’t help to circulate a lot of minutiae.
Even minutiae can create the Superpanopticon.
Facebook itself has been likened to a digital panopticon since at least 2007, though there are issues both with some of these critiques and with responses to them. The “Facebook=Panopticon” theme emerges anew each time the site redesigns its privacy settings—for instance, following the launch of so-called “frictionless sharing”—or, in more recent Facebook-speak, every time the site redesigns its “visibility settings.” Others express skepticism, however, as to whether the social media site is really what I jokingly like to call “the Panoptibook”; they claim that Facebook’s goal is supposedly “not to discipline us,” but to coerceus into reckless sharing (though I would argue that the latter is merely an instance of the former).
Others point to the fact that using Facebook is still “largely voluntary”; therefore, it cannot be the Panopticon. ‘Voluntary,’ however, is predicated on the notion of free choice, and as I argued in Part I, our choices here are constrained; at best, each of us can only choose whether or not to interact with Facebook (or other digital social technologies) directly. Infinitely expanding definitions of ‘disclosure’ notwithstanding, whether we leave digital traces on Facebook depends not just on the choices we make as individuals, but on the choices made by people to whom we are connected in any way. For most of us, this means that leaving traces on Facebook is largely inevitable, whether “voluntary” or not.
Looks like someone has a case of documentary vision!
What may not be as readily apparent is that whether or not we interact with the site directly, Facebook and other social media sites also leave traces on us. Nathan Jurgenson (@nathanjurgenson) describes “documentary vision” as an augmented version of the photographer’s ‘camera eye,’ one through which the infinite opportunity for self-documentation afforded by social media leads us not only to view the world in terms of its documentary potential, but also to experience our own present “as always a future past.” In this way, “the logic of Facebook” affects us most profoundly not when we are using Facebook, but when we are doing nearly anything else. Away from our screens, the experiences we choose and the ways we experience them are inexorably colored not only by the ways we imagine they could be read by others in artifact form, but by the range of idealized documentary artifacts we imagine we could create from them. We see and shape our moments based on the stories we might tell about them, on the future histories they could become.
I argue here, however, that Facebook’s phenomenological impact is not limited to opportunities for self-documentation. More and more, we are attuned not only to possibilities of documenting, but also to possibilities of being documented. As I explored in Part I of this essay, living in an augmented world means that we are always connected to digital social technologies (whether we are connecting to them or not). As I elaborated in last month’s Part II, the Shame On You paradigm reminds us that virtually any moment can be a future past disclosure; we also know that social media and digital social technologies are structured by the Look At Me paradigm, which insists that “any data that can be shared, WILL be shared.” Consequently, if augmented reality has seen the emergence of a new kind of ‘camera eye’, it has seen as well the emergence of a new kind of camera shyness. Much as Bentham designed the Panopticon to crowd-source the disciplinary work of prison guards, Facebook’s design ends up crowd-sourcing the disciplinary functions of the paparazzi.
Camera shy.
Accordingly, I extend Jurgenson’s concept of documentary vision—through which we are simultaneously documenting subjects and documented objects, perpetually aware of each moment’s documentary potential—into what I term documentary consciousness, or the perpetual awareness that, at each moment, we are potentially the documented objects of others. I want to be clear that it is not Facebook itself that is “the Panoptibook”; knowing something about nearly everyone is not nearly the same thing as seeing everything about anyone. Moreover, what Facebook ‘knows’ comes not only from what it ‘sees’ of our actions online, but also from the online and offline actions of our family members, friends, and acquaintances. Our loved ones—and our “liked” ones, and untold scores of strangers—are at least as much the guard in the Panopticon tower as is Facebook itself, if not moreso. As a result, we are now subjected to a second-order asymmetrical gaze: we can never know with certainty whether we are within the field of someone else’s documentary vision, and we can never know when, where, by whom, or to what end any documentary artifacts created of us will be viewed.
As Erving Goffman elaborated more than 50 years ago, we all take on different roles in different social contexts. For Goffman, this represents not “a lack of integrity,” but the work each of us does, and is expected to do, in order to make social interaction function. In fact, it is those individuals who refuse to play appropriate roles, or whose behavior deviates from what others expect based on the situation at hand, who lose face and tarnish their credibility with others. The context collapse designed into most social media therefore complicates profoundly even the purposeful, asynchronous self-presentation that takes place on such websites, which has come to require “laborious practices of protection, maintenance, and care.”
Attempting the impossible.
When we internalize the abstracted and compounded documentary gaze, we are left with a Sisyphean disciplinary task: we become obligated to consider not just the situation at hand, and not just the audiences we choose for the documentary artifacts we create, but also every future audience for every documentary artifact created by anyone else. It is no longer enough to play the appropriate social role in the present moment; it is no longer enough to craft and curate images of selves we dream of becoming, selves who will have lived idealized versions of our near and distant pasts. Applying technologies of self starts to bring less pleasure and more resignation, as documentary consciousness stirs a subtle but persistent disquietude; documentary consciousness haunts us with the knowledge that we cannot be all things, at all times, to all of the others that we (or our artifacts) will ever encounter. Documentary consciousness entails the ever-present sense of a looming future failure.
As I discussed in Part II, the impacts of these inevitable failures are not evenly distributed. Those who have the most to lose are not people who are “evil” or who are “doing something they shouldn’t be doing,” but people who live ordinary lives within marginalized groups. Those who have the most to gain, on the other hand, are people who are already among the most privileged, and corporations that already wield a great deal of power. The greatest burdens of documentary consciousness itself are therefore likely to be carried by people who are already carrying other burdens of social inequality.
Recent attention to a website called WeKnowWhatYoureDoing.com showcased much of this yet again. The speaker behind the “we” is a white, 18-year-old British man named Callum Haywood (who’s economically privileged enough to own an array of computer and networking hardware), who built a site that aggregates potentially incriminating Facebook status updates and showcases them with the names and photos of the people who posted them. Because all the data used is “publicly accessible via the Graph API,” Haywood states in a disclaimer on the site that he “cannot be held responsible for any persons [sic] actions” as a result of using what he terms “this experiment”; he has further stated that his site (which is subtitled, “…and we think you should stop”) is intended to be “a learning tool” for those users who have failed to “properly [understand] their privacy options” on Facebook.
Not everyone thinks Facebook’s privacy settings are easy to understand.
Coverage of the site’s rapid rise to popularity (or at least high visibility) was similar to coverage surrounding Girls Around Me: a lot of Shame On You, and the occasional critique that stopped at “creepy.” Tech–savvywhitemen thought the site was great; a young white woman starting college at Yale this fall explained that her digital cohort—“the youngest millennials, the real Facebook Generation”—has learned from the mistakes of “those who are ten years older than us.” As a result, her generation thinks Facebook’s privacy settings are easy, obvious, and normal; if your mileage has varied, “you have no one to blame but yourself.” In examining the screenshots from WeKnowWhatYoureDoing.com that these articles feature, I have yet to find one featured Facebook user who writes like a Yale-bound preparatory school graduate; unlike the articles’ authors, the majority of featured Facebook users in these screenshots are people of color. It is hard not to see WeKnowWhatYoureDoing.com as doing anything other than offering self-satisfied amusement to privileged people, at the acknowledged potential expense of less privileged people’s employment.
Even overlooking the facts that Facebook’s privacy policy may be “more confusing and harder to understand than the small print coming from credit card companies,” and that the data in Facebook’s Graph API is really only “publicly accessible” in reference to a ‘public’ comprised entirely of software developers, the story Haywood wants to tell with WeKnowWhatYoureDoing.com is fundamentally flawed. It is a story in which “people violate their own privacies on a regular basis,” in a world where digital surveillance, companies like Facebook, and smug self-important software developers fade into the background of the setting’s ‘natural’ world. Haywood states, “[p]eople have lost their jobs in the past due to some of the posts they put on Facebook, so maybe this demonstrates why”; what he seems to be missing is that his site demonstrates not only “why,” but how people come to lose their jobs.
In pretending that “information wants to be free” and holding individuals responsible for violations of their own privacy, we neglect to consider the responsibility of other individuals who write code for companies like Facebook, or who use the data available through the Graph API, or who circulate Facebook data more widely, or who help Facebook generate and collect data (yes, even by tagging their friends in photographs). If we cannot control our own privacy, it is because we can so easily impact the privacy of everyone we know—and even of people we don’t know.
We need to take a new look at “privacy” and “autonomy.”
We urgently need to rethink ‘privacy’ in ways that expand beyond the level of individual conditions, obligations, or responsibilities, yet also take into account differing intersections of visibility, context, and identity in an unequal but intricately connected society. And we need as well to turn much of our thinking about privacy and individual autonomy on its head. Due justice to questions of who is visible, and to whom, to what end, and to what effect cannot be done so long as we continue to believe that privacy and visibility are simply neutral consequences of individual choices, or that such choices are individual moral responsibilities.
We must reconceptualize privacy as a collective condition, one that entails more than simply ‘lack of visibility’; privacy must be also a collective responsibility, one that individuals and institutions alike honor in ways that go beyond ‘opting out’ of the near-ubiquitous state and corporate surveillance we seem to take for granted. It is time to stop critiquing the visible minutiae of individual lives and choices, and to start asking critical questions about who is looking, and why, and what happens next.
[i] Note that “publicly available” is tricky here: Girls Around Me users were ported to Facebook to view the women’s profiles, and so could also have accessed non-public information if they happened to view profiles of women with whom they had friends or networks in common.
[ii] Alternatively, my difficulty finding posts written in support of Google’s policy may simply reflect Google’s ‘personalization’ of my search results, both then and now.
About Cyborgology
We live in a cyborg society. Technology has infiltrated the most fundamental aspects of our lives: social organization, the body, even our self-concepts. This blog chronicles our new, augmented reality.











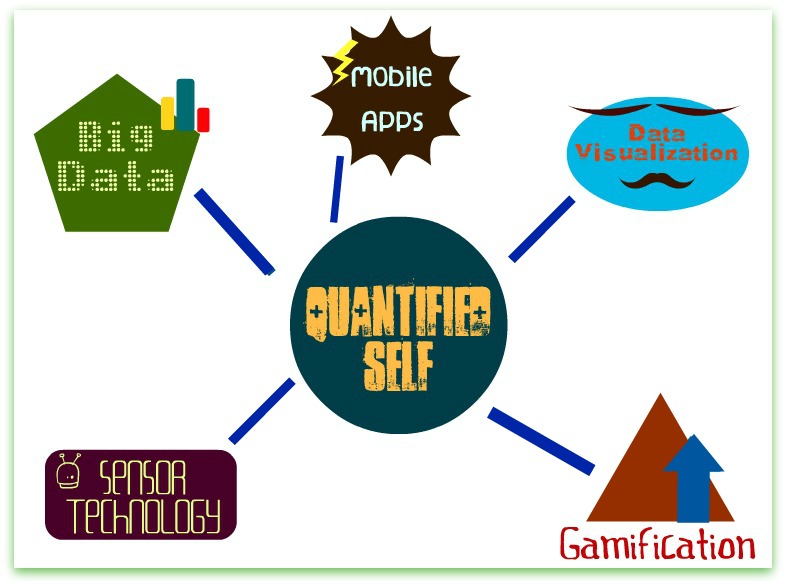
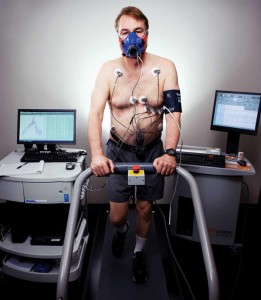





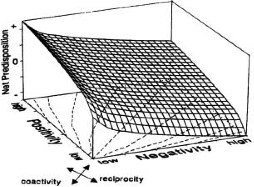











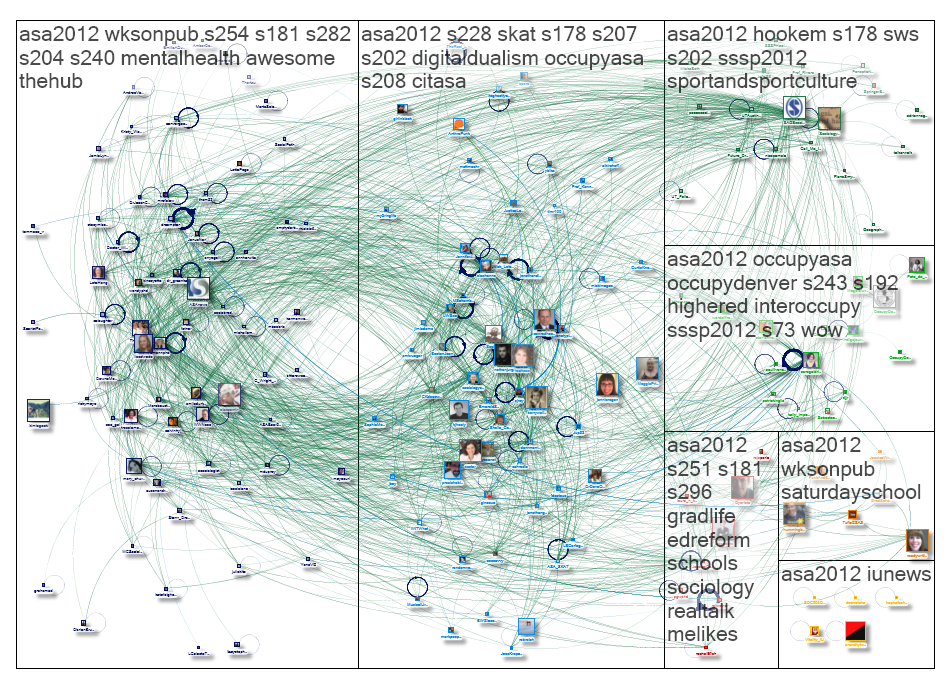
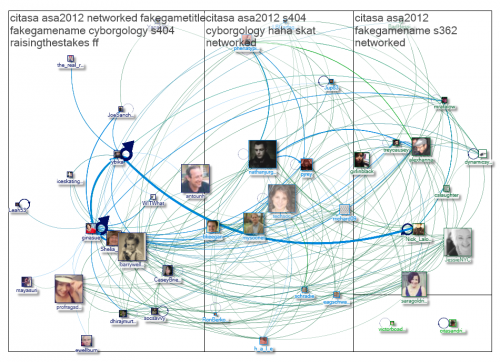


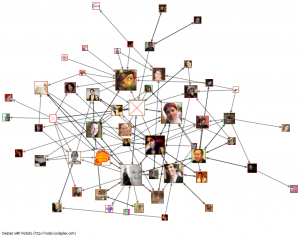


























{kind=link}
{kind=link}
{kind=link}
{kind=link}