In the 6-minute video below, Stanford sociologist Aliya Saperstein discusses her research showing that the perception of other peoples’ race is shaped by what we know about them. She uses data collected through a series of in-person interviews in which interviewers sit down with respondents several times over many years, learn about what’s happened and, among other things, make a judgment call as to their race. You may be surprised how often racial designations. In one of her samples, 20% of respondents were inconsistently identified, meaning that they were given different racial classifications by different interviewers at least once.
Saperstein found that a person judged as white in an early interview was more likely to be marked as black in a later interview if they experienced a life event that is stereotypically associated with blackness, like imprisonment or unemployment.
She and some colleagues also did an experiment, asking subjects to indicate whether people with black, white, and ambiguous faces dressed in a suit or a blue work shirt were white or black. Tracing their mouse paths, it was clear that the same face in a suit was more easily categorized as white than the one in a work shirt.
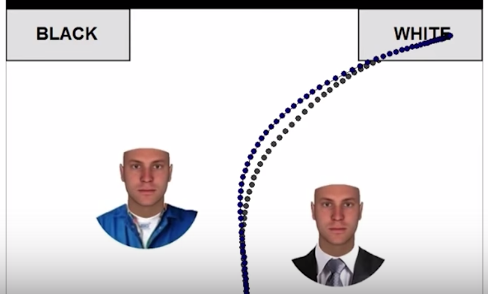
Race is a social construction, not just in the sense that we made it up, but in that it’s flexible and dependent on status as well as phenotype.
She finishes with the observation that, while phenotype definitely impacts a person’s life chances, we also need to be aware that differences in education, income, and imprisonment reflect not only bias against phenotype, but the fact that success begets whiteness. And vice versa.
Watch the whole thing here:
[youtube]https://www.youtube.com/watch?v=jiwieME2tis[/youtube]
The Colbert Report also referenced Saperstein’s work:
Lisa Wade, PhD is an Associate Professor at Tulane University. She is the author of American Hookup, a book about college sexual culture; a textbook about gender; and a forthcoming introductory text: Terrible Magnificent Sociology. You can follow her on Twitter and Instagram.