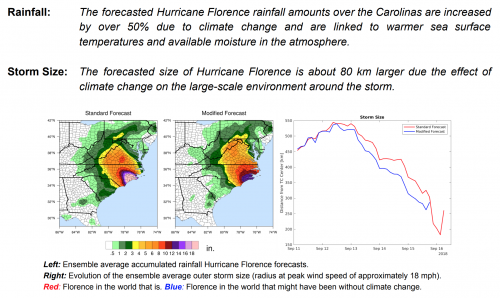
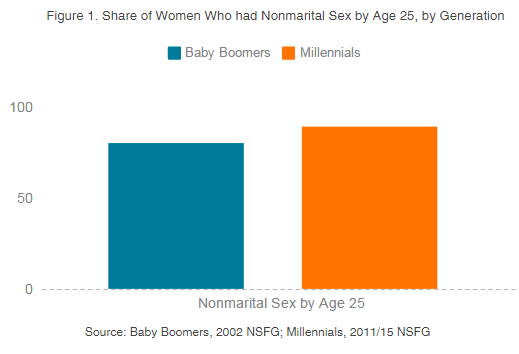
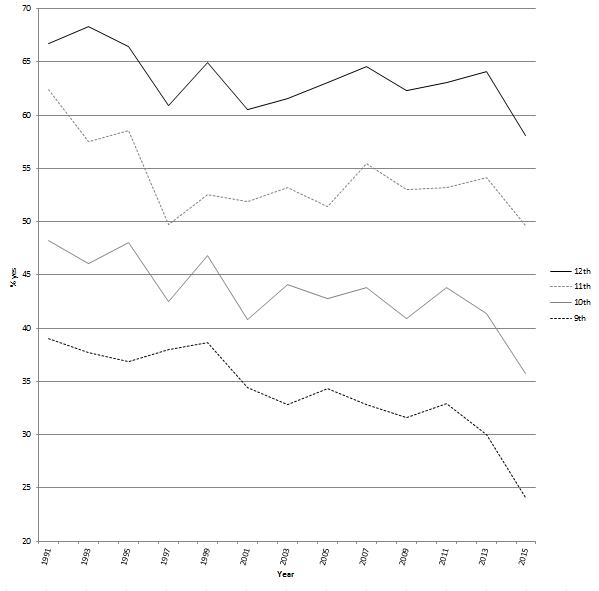
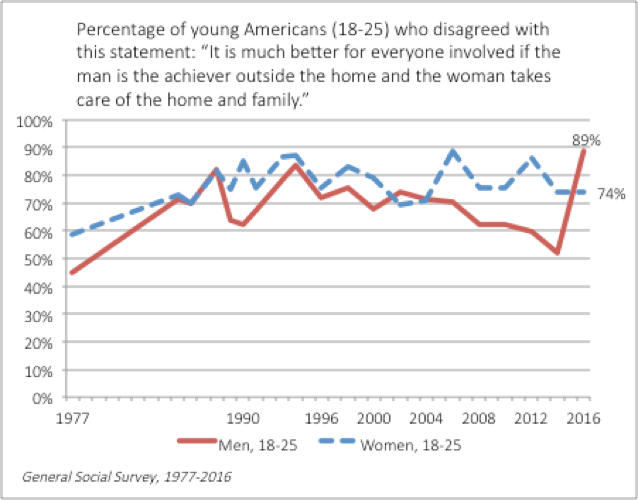
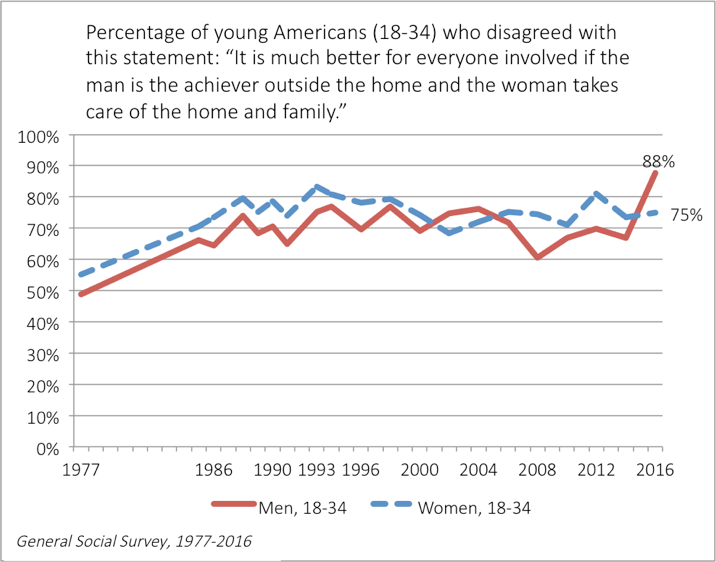
Everyone has been talking about last week’s Senate testimony from Christine Blasey Ford and Supreme Court nominee Brett Kavanaugh. Amid the social media chatter, I was struck by this infographic from an article at Vox: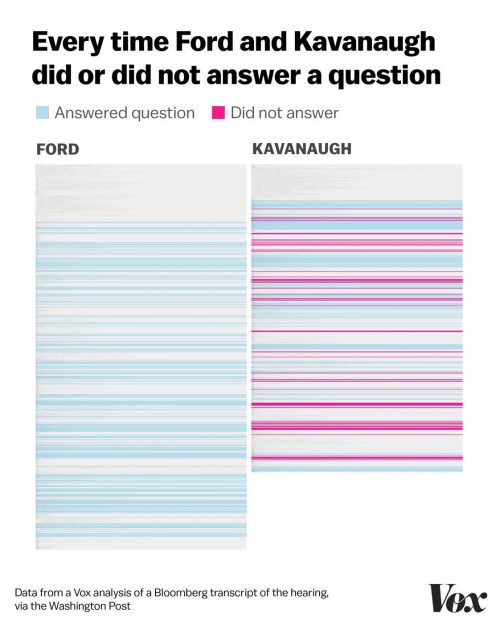
Commentators have noted the emotional contrast between Ford and Kavanaugh’s testimony and observed that Kavanaugh’s anger is a strategic move in a culture that is used to discouraging emotional expression from men and judging it harshly from women. Alongside the anger, this chart also shows us a gendered pattern in who gets to change the topic of conversation—or disregard it altogether.
Sociologists use conversation analysis to study how social forces shape our small, everyday interactions. One example is “uptalk,” a gendered pattern of pitched-up speech that conveys different meanings when men and women use it. Are men more likely to change the subject or ignore the topic of conversation? Two experimental conversation studies from American Sociological Review shed light on what could be happening here and show a way forward.
In a 1994 study that put men and women into different leadership roles, Cathryn Johnson found that participants’ status had a stronger effect on their speech patterns, while gender was more closely associated with nonverbal interactions. In a second study from 2001, Dina G. Okamoto and Lynn Smith-Lovin looked directly at changing the topic of conversation and did not find strong differences across the gender of participants. However, they did find an effect where men following male speakers were less likely to change the topic, concluding “men, as high-status actors, can more legitimately evaluate the contributions of others and, in particular, can more readily dismiss the contributions of women” (Pp. 867).

The important takeaway here is not that gender “doesn’t matter” in everyday conversation. It is that gender can have indirect influences on who carries social status into a conversation, and we can balance that influence by paying attention to who has the authority to speak and when. By consciously changing status dynamics —possibly by changing who is in the room or by calling out rule-breaking behavior—we can work to fix imbalances in who has to have the tough conversations.
Evan Stewart is an assistant professor of sociology at University of Massachusetts Boston. You can follow his work at his website, on Twitter, or on BlueSky.