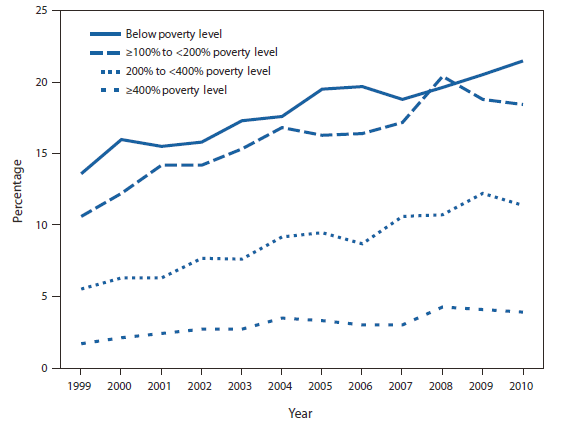
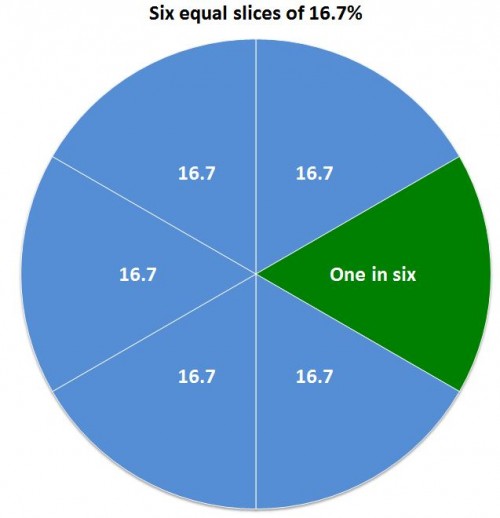
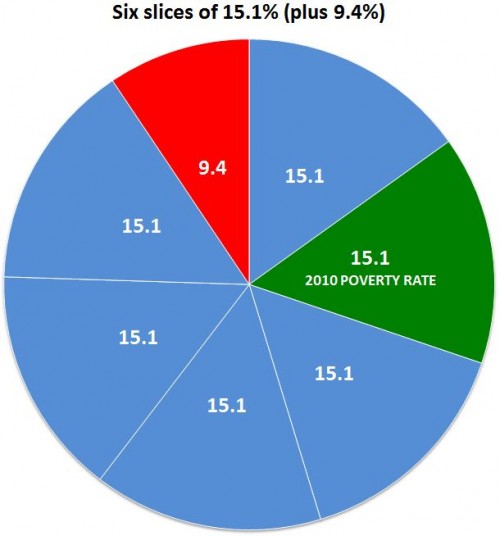
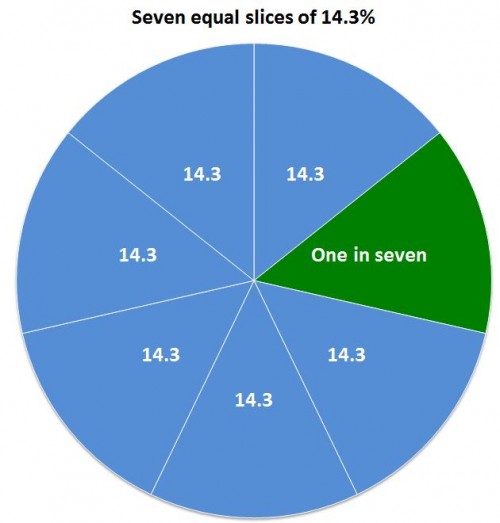
At Flowing Data, the Venn Diagram illustrated by a platypus playing a keytar. Go there.
Lisa Wade, PhD is an Associate Professor at Tulane University. She is the author of American Hookup, a book about college sexual culture; a textbook about gender; and a forthcoming introductory text: Terrible Magnificent Sociology. You can follow her on Twitter and Instagram.