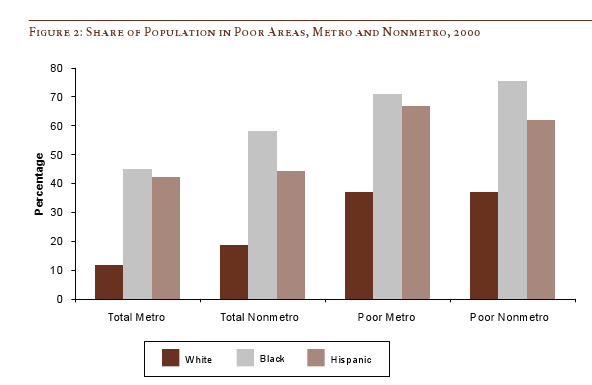
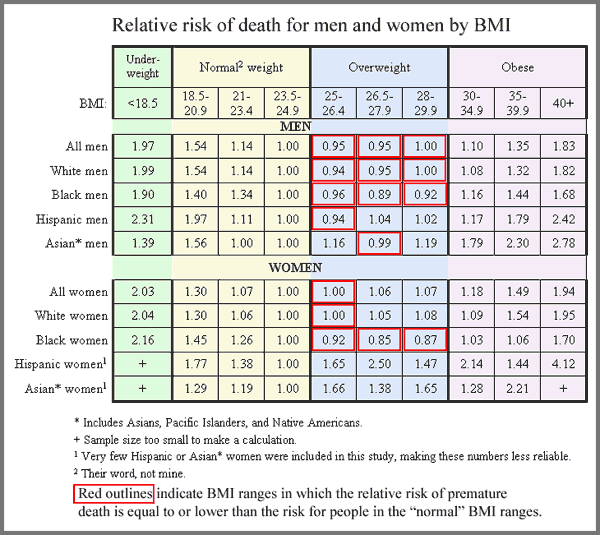
Using the same OECD data set that produced this graph on time spent eating and BMI, Floyd Norris at the New York Times brings us a new finding. The “10 countries where people spend less than 100 minutes eating and drinking each day have, as a group, consistently shown higher economic growth than those that took more than 100 minutes to savor their daily repasts.”
 As before, the statistics are far from conclusive, but the data continues to invite a discussion about food and culture.
As before, the statistics are far from conclusive, but the data continues to invite a discussion about food and culture.
It also invites a discussion of atheoretical data analysis. Last year, Chris Anderson’s article in Wired Magazine (The End of Theory: The Data Deluge Makes the Scientific Method Obsolete) argued that our ability to generate vast amounts of data, made theory unnecessary, and that scientists were starting to look at correlations as a sufficient analysis level of analysis.