
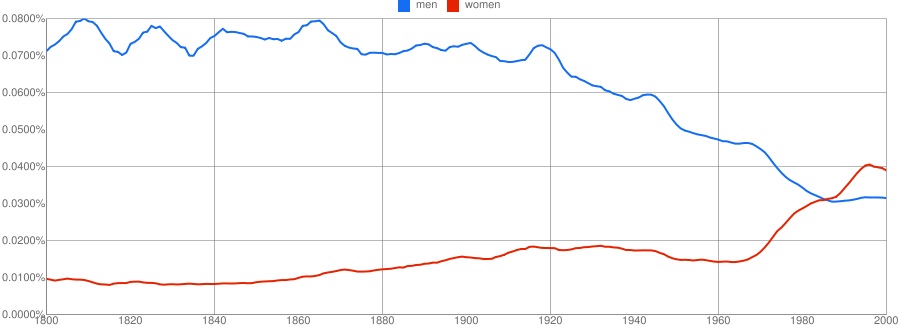
A number of readers, including Mickey C., Lu Fong (writer and editor at The Good Men Project and Good Feed), Cheryl S., and Kelly V., let us know about Google Ngram. The program includes a database of a little over 5 million books and allows you to graph the frequency with which various words or phrases show up in books published in various languages over time (English can also be broken down into British or American English). Mickey and Lu each graphed the words “men” and “women” (see Lu’s discussion here):
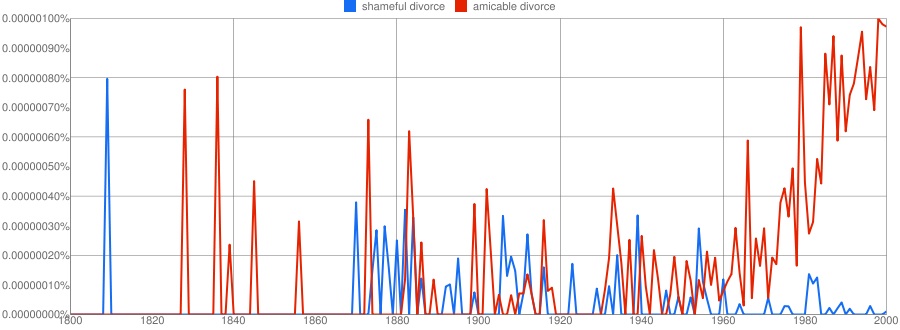
Cheryl S. tried “shameful divorce” vs. “amicable divorce”:

The plateaus are due to smoothing, which presents the data as 3-year averages to reduce huge spikes and valleys from individual data points to make overall trends more apparent. You can change the level of smoothing. Here’s the graph with no smoothing at all:
Overall, the tool provides a way to track changes in language as well as social trends. Google provides some info on their methodology, though not as much as I’d like. Some key points:
1. They “normalize” the results based on the number of books published each year, to account for the fact that many more books are published each year now than in, say, 1800, so 100 occurrences of a phrase today means less than 100 occurrences then — that’s why results are presented as percentages, not as raw numbers.
2. Phrases have to appear in at least 40 books total to be included in the database.
3. Keep in mind, the dataset is not based on all books published, but of a subset of books digitized by Google Books. The database includes about 4% of all published books, according to a journal article just published in Science.
I suspect it will be an amazing time-killer.
Comments 16
Ollie — December 19, 2010
For some reason the word "muggle" shows up in the 1800's...
RGR — December 19, 2010
Okay, but look what happened with "men" and "women" around 2002, when you extend the dates all the way to 2008 (which was the newest date permitted):
("men" surpasses "women" again).
http://30.media.tumblr.com/tumblr_ldp4479hGL1qcushgo1_500.jpg
In what looks like the biggest man-spike since the 1970 or earlier!
Rachael — December 19, 2010
Oh my God, I could do this for hours.
Eddy — December 19, 2010
It's interesting to search for "he" and "she" - who are the characters in our books? http://img843.imageshack.us/i/screenshot4yt.png/
Also interesting: "he said" and "she said" - who speaks in our books? http://img90.imageshack.us/i/screenshot3db.png/
Chris — December 19, 2010
Try "sex" and "love"...so cool! There goes my night
C — December 20, 2010
Looking at the use of the word "Oriental" is pretty interesting, as is contrasting its vast divergence with the incorrect use of the term "oriental" (case sensitive) past roughly 1830.
Treefinger — December 20, 2010
http://ngrams.googlelabs.com/graph?content=prostate%2C+clitoris&year_start=1800&year_end=2000&corpus=0&smoothing=3
I have no idea what this means (an uptick in prostate cancer dramas? There are more ways to non-sexually involve prostates in books that clitorises? Somehow an organ most men don't know they have has made it into more depictions of sex than the clitoris?), but I guess it's interesting. I wonder what these books are- if there are more fiction books? Medical books?
And yes, if you're wondering, I was the person that looked up all the rude words first when given a dictionary.
Tori — December 20, 2010
Hi all; take a look at UNC Professor Philip Cohen's Google experiment with occurrences of "family" words over time:
http://familyinequality.wordpress.com/2010/12/20/horizontal-and-vertical-family-relationships-literarily/.
Yields some interesting food for thought re: differences in inter-generational relationships as rates of fertility and life expectancy have undergone a sea-change in the last 200 years.
Google Ngram – Ein Zeittotschläger oder ein sinnvolles Tool? « Afrika Wissen Schaft — December 21, 2010
[...] ich Ngram vielleicht erst in ein paar Jahren entdeckt. Gestern wurde dort unter dem Titel „Database on Linguistic Trends in Books„ ein Beitrag zu Ngram [...]
Jeremy Klein — April 26, 2024
Databases are a complex structure. To manage it properly, you need experience and relevant knowledge. I can recommend https://dbserv.com/managed-dba-services as proven specialists who know their job.
Jeremy Klein — April 26, 2024
Database systems are intricate constructs that require adept handling. Successfully navigating them demands not only experience but also a deep understanding of their nuances. When seeking proficient management, consider entrusting the task to seasoned experts who possess the requisite expertise. For reliable support and optimized performance, I highly recommend exploring the services offered by https://dbserv.com/managed-dba-services. Their track record speaks volumes about their proficiency in this field. With their assistance, you can ensure that your database operations are in capable hands, allowing you to focus on your core business objectives without the burden of technical intricacies.
KatrinFedotova — April 26, 2024
It's really hard to understand. You need to be able to handle a lot of information