

Over the past decade, theorizing about data and digital mediums has typically been kept to spaces like New Media Studies. The rise of Digital Humanities as a strictly empirical field cuts against this grain in a manner worth examining. Part I: The Hegemony of Data, discusses a longer history of information to evaluate the intuitive sense of objectivity that surrounds “Big Data”. Part II: The Heavens and Hells of the Web examines the initial beliefs in digital messianism as a method of eliminating moral and social problems, how they turned apocalyptic, and what lessons Digital Humanities should take from it. Part III: Digital Epistemology goes beyond critique and builds a sense in which anti-colonial, anti-capitalist, moral visions of a future may benefit and actually advance discourses through our experiences with digital tools and society.
“Epiphany” is a good description of my first encounter with Matthew Jockers’ Macroanalysis in 2014. Having come into the discipline history from a New Atheist Rational euphoric high, Macroanalysis struck me with its possibility for an entirely objective method of history. Jockers emphasized this possibility, by displacing the term “reading” with “analysis.” Where the formerwas entirely too close to problems of selectivity and bias, the latter emphasized the impartial potential of “big [literary] data.” Whereas before, we were all bound by the number of texts we could read in a single lifetime, Macroanalysis invited a more scientific approach to literature:
Today, however, the ubiquity of data, so-called big data, is changing the sampling game. Indeed, big data are fundamentally altering the way that much science and social science get done…
…These massive digital-text collections are changing how literary studies get done. Close reading is not only impractical as a means of evidence gathering in the digital library, but big data render it totally inappropriate as a method of studying literary history. (p. 7)
The vision of arbitration-by-analysis has struck even the most interpretive of fields with considerable force. This is partially because we were primed for this vision of our future: an aristocracy of numbers where not only research, but also morality, ethics, and politics would be dictated by formulas that transcended mere human interest. That we presently take this reliance on data to religious proportions should invite some curiosity as to how life got to this point; in other words, Jockers’ faith in data asks us to historicize the ascension of data hegemony.
A reasonable starting point for this conversation is the development of the web. For both advocates and opponents, the web represents a requirement for the expansive role that data currently plays in society. That Google now stands in as the paragon of human knowledge only exemplifies the sense that the web was and continues to be essential to the current discussions about the Information Age. But how does our intuition compare to the (recent) history of data itself?
In 1964, the engineer Paul Baran published an eleven-volume proposal titled On Distributed Communications, which evaluated a method of rudimentary network connections between universities, military bases, and corporate labs across the country. Deeply influential to the development of ARPANET some five years later, Baran established many of the first packet switching protocols used to distribute information through a network. Baran’s proposal connected several of these regional networks for the purpose of creating a redundancy of data. This redundancy decentralized data in a manner that could preserve it in the worst-case scenario of nuclear war. If New York was lost in nuclear winter, labs at Berkeley, Chicago, and Texas would retain all the files that scientists and military researchers had collected on the east coast.
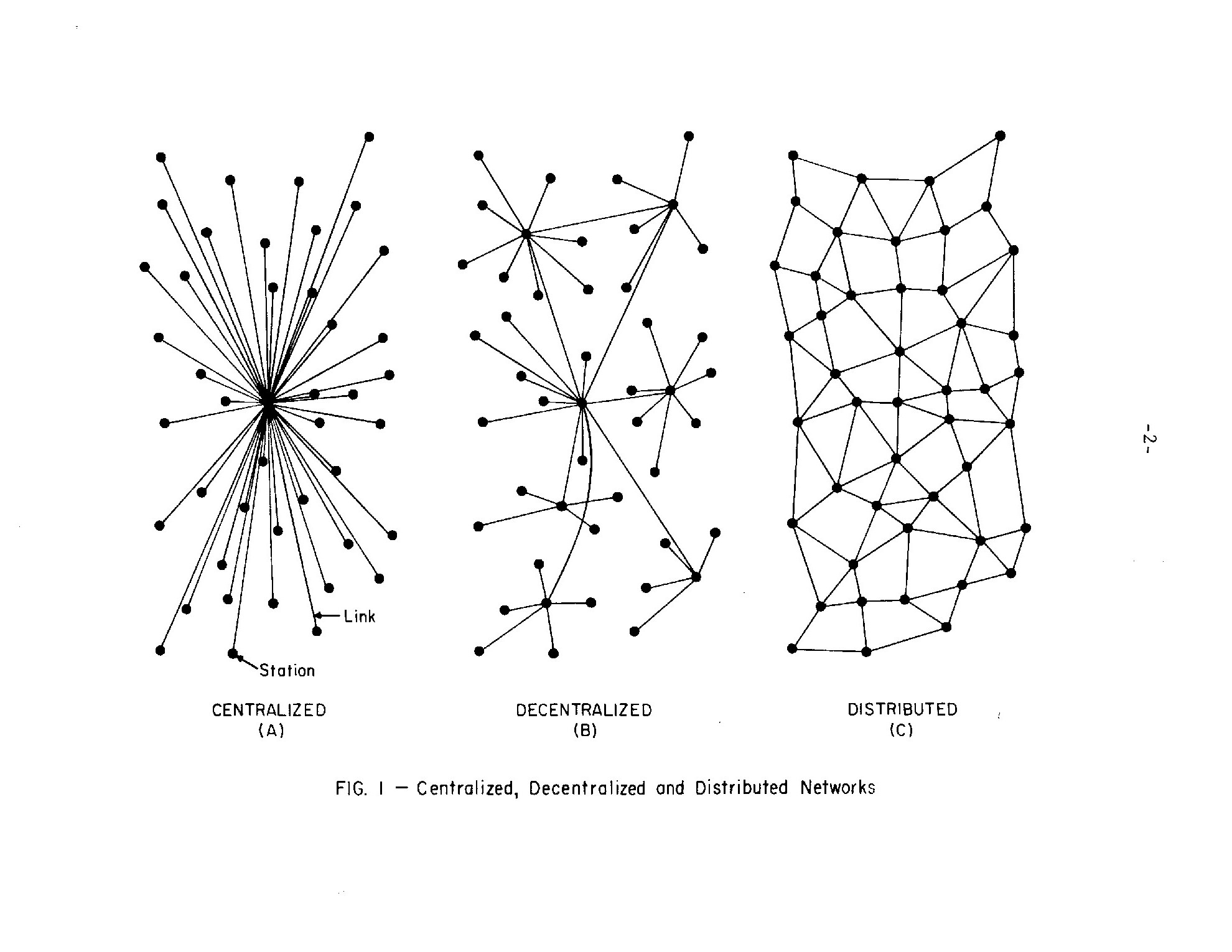
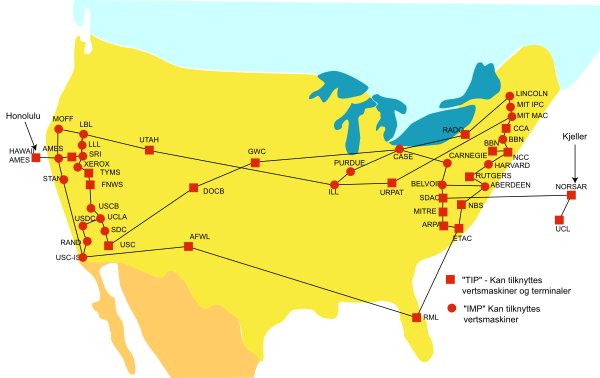
The redundancy of data was a useful method to ensure its survivability. (Volume I, p. ii) This aspect of the project was so important that in volume XI, Baran claimed that it was “survivability” that served as their top criterion for the proposal (Volume XI, p. 5). But much like any new technology, its cost was not cheap. Baran estimated a 234 million dollar initial investment cost, with a 60 million dollar annual maintenance estimate for the first ten years of the system; in comparison the Department of Defense had typically budgeted 1 billion a year for communications projects. (Volume X, p. 1-2) The web didn’t lead to the hegemony of data; rather, the hegemony of data led to a demand for the web.
This demand invites us to ask what work data was doing at the time. Three years before Baran submitted his report, President Kennedy appointed the civilian bureaucrat Robert McNamara to Secretary of Defense, an unusual move, given McNamara’s lack of battle experience. Prior to his arrival as the boss of the United States military, McNamara had spent part of WWII using his experience in data analysis with the Air Force: determining, for example, at what altitude to drop bombs in order to maximize enemy casualties and minimize friendly fire. McNamara’s efforts—which became known as “systems analysis”—joined with Abraham Wald’s work in statistical analysis, and Alan Turing’s more famous work in breaking the Enigma code machine, all of which demonstrated the significance of data for rendering military battles more efficient. Against an earlier tradition of warfare in which honor, masculinity, and birthright had all played prominent roles in the development of an aristocratic army, data had transformed war from something waged into something managed.
In the transition to “peace,” the extension of these statistical skills in civilian management seemed only logical, something emphasized by a policy wonk under McNamara. In 1966, E. S. Quade proposed that the work “systems analysis” did for the military should be used to manage civilian affairs as well. While Quade was careful to consistently acknowledge the limitations of the approach, he nevertheless suggested that this approach of efficiency could be used in things like the postman’s route, urban redevelopment, and welfare planning. The goal for these projects would ultimately be efficiency; it set aside questions of morality, instead emphasizing ambiguous utilitarian perspectives on the organization of civil society:
The key to a successful analysis is a continuous cycle of formulating the problem, selecting objectives, designing alternatives, collecting data, building models, weighing cost against performance, testing for sensitivity, questioning assumptions and data, re-examining the objectives, opening new alternatives, building better models and so on, until satisfaction is obtained or time or money force a cutoff. (Quade, 2006, 10-11)
It is here that we see the full stakes of a slow elision between efficiency and morality. The hegemony of data created a very specific vision of the future: data through methodological innovations would consistently produce a society that privileged maximizing efficiency. At best, efficiency ran parallel to moral advancements in society; at worst, it was entirely oblivious to moral visions for a better world. In the context of the war, such efficiency dedicated to the preservation of human life could be wed to an anti-Nazi morality with few problems. In peacetime, the hegemony of data was a lynchpin of US imperialism against the Soviet Union. In other words, its objectivity was only guaranteed insofar as its users took the military power of the United States as an unqualified good.
Corporations were not the only players in this gradual transition from method of management into mode of moral politics. At a 1939 symposium, the economist Frank Knight–a teacher of Milton Friedman–had suggested changing a quote from Lord Kelvin that had been inscribed upon the Social Sciences Building at the University of Chicago to the following: “If you cannot measure, measure anyhow.” Taking up this challenge, the economic historian Robert Fogel arrived at the University of Chicago in 1964, where he began work on the most controversial history book of the late-twentieth century. It was published in 1976 with the title Time on the Cross, which introduced McNamara’s systems-analysis methodology into history and called it “cliometrics.” The book rejected the long-held assumption that slavery stunted capitalism and instead used the analysis of data to argue that plantations had in fact been most profitable immediately before to the Civil War.
Historical debate aside, cliometrics most directly challenged the ways that historical research was undertaken. Much like Jockers, the authors of Time on The Cross–an interdisciplinary, collaborative book if ever one existed–juxtaposed the empirical certainty of plantation data against the interpretive mode of historical research, a mode they associated with the “ideological pressures of writing about the American system of slavery.” Fogel & Stanley Engerman (his co-author of the book) did not deny that interpretation had some role to play in historical work; the cliometrician instead viewed it as a method that should be used sparingly, only where no quantitative data could be produced for analysis and accordingly viewed interpretation as quite close to speculation.
This is, in fact, the climax of contestation under data hegemony. Whereas historians had–and still do, for the most part–elected to perform their work embracing the necessary, ruthless selectivity that comes with distilling centuries of time into hundreds of pages, Fogel and the rising crop of cliometricians instead echoed Knight’s command for the social scientist. The hegemony of data for these folks produced a very different vision of slave society, one in which the plantation became an efficiency-maximizing, rational agent. Sources that emphasized the violence and brutality against slaves were consequently viewed as “exaggerated” and research on such sources as “ideological.”
It is worth taking seriously how Fogel & Engerman conceived of slave agency to see how deeply the language of efficiency pervaded their work. Less a pathological racism that saw African Americans and slaves as subhuman, they actually conceived themselves as “rescuing” African Americans from history through an account of their ingenuity and industriousness as slaves:
The typical slave fieldhand was not lazy, inept, and unproductive. On average, he was harder-working and more efficient than his white counterpart. (5)
Throughout the text, both authors commit to showing a slave capable of becoming efficient through an assimilation and transformation of the Protestant Work Ethic. The question of whether or not efficiency is a good manner of measuring human worth is never raised. While both authors had retracted their perspectives on violence on the plantations by the 1980s, this vision of demonstrating “rationality” and “efficiency” for a group of marginalized people in order to account for their history was only possible in a world where such quantitative data was the only objective method to describe them. In other words, the question of whether slavery was a moral good was a question that conveniently fell outside the purview of the data analyst.
This is a lasting influence of the transition from interpretation to analysis. In a heavily-critiqued piece published last year on the Digital Humanities, David Golumbia, Daniel Allington & Sarah Brouillette argued precisely that this was the general, if subconscious direction of the DH field: fetishize the collection of data, program for the analysis, cease interpretation. Despite all the critiques, very few respondents addressed directly the issue of data-collection, except to again proselytize about the natural power of big data. At this point, it should be clear that this naturalization had always been a political process, despite the best efforts of Jockers to render literary studies an analytical, objective science.
Historicizing the role of data has given us a feel for the tension that existed between the gathering of information and the subsequent loss of a particular political imagination. On a whole, many proponents of the Digital Humanities field think even less critically than Matthew Jockers about the limits and possibilities of digitization in disciplines like literature, history, and anthropology. Instead, many of the textbooks that introduce programming and data collection into these fields typically trot out lines about the radical accessibility, dynamic possibilities, or digital revolution. These clichés have long since played out in fields like New Media Studies or Game Studies, where astute critics like Lisa Nakamura have pointed out that being online did not eliminate social or political inequalities offline. The humbling of digital utopia in these fields ought to ensure Digital Humanities ask itself a question: what interpretive work is being done in the collection, systematization, digitization, and publication of literary and historical data, and what are we losing in the process? It is at the intersection on this question between these fields that Part II will turn.
I would like to thank Sarah Brouillette for reading an early draft of this piece. I would also like to point towards two more sources asking particularly good questions on this front: the first is Bernard Harcourt’s 2011 Aims of Education speech titled “Questioning the Authority of Truth” from which I first learned of Robert McNamara’s story. Second is Lara Putnam’s 2016 AHR article “The Transnational and the Text Searchable,” which critically theorizes the role of digital sources and searches in the pursuit of historical research.
Marley-Vincent Lindsey is a doctoral student in history at Brown. He tweets on occasion.