
Sound happens when things vibrate, displacing air and creating pressure waves that fall within the spectrum of waves the human ear can detect.
Researchers at MIT, working with Microsoft & Adobe, have developed an algorithm that reads video recordings of vibrating objects more or less like a microphone reads the vibrations of a diaphragm. I like to think it turns the world into a record: instead of vibrations etched in vinyl, the algorithm reads vibrations etched in pixels of light–it’s a video phonograph, something that lets us hear the sounds written in the recorded motion of objects. As researcher Abe Davis explains,
We’re recovering sounds from objects. That gives us a lot of information about the sound that’s going on around the object, but it also gives us a lot of information about the object itself, because different objects are going to respond to sound in different ways.
So, this process gives us info about both the ambient audio environment, and the materiality of the videorecorded objects–that’s a lot of information, info that could obviously be used for all sorts of surveillance. And that will likely be people’s primary concern with this practice.
But I think this is about a lot more than surveillance. This research reflects some general trends that cross both theory, pop culture, and media/tech:
1. The privileging, and close interrelationship, between sound and materiality. “New Materialism” is a really trendy field in the theoretical humanities and cultural studies. But if you read new materialists carefully, they rely on a lot of sonic vocabulary (“attunement” is probably the most common of these terms), and these sonic terms do a lot of theoretical work. I would argue (well, I AM arguing in this new manuscript I’m writing) that one of the things that is “new” about this “materialism” is its sonic, rather than visual, epistemology. We’re re-conceiving what matter is and how it works, and to do this we’re relying on a very specific understanding of what sound is and how it works. The unexamined question here is, obviously: so what’s this understanding of sound? I think close readings of studies like this can help us unpack how advances in technology are impacting the dominant concept of “sound” and “listening,” and how these concepts in turn inform new materialist theory.
2. Our dominant, commonsense concepts of sound and listening are changing as technology changes. But these technologies are tied to older ones–in this case, I can see connections to telephony and optical sound (used most famously on early sound films).
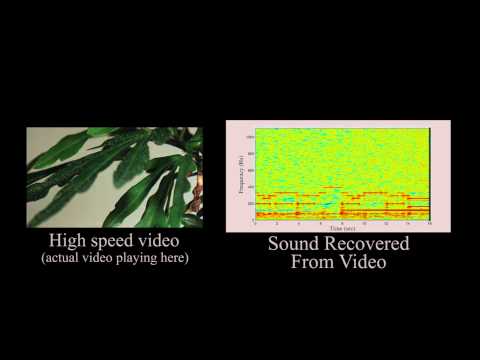
The process the researchers use to process the video frames seems related to AutoTune: instead of smoothing out off-pitch parts (which is what AutoTune does), this MIT algorithm amplifies sonic irregularities to help differentiate among sonic events and their qualities (timbre, rhythm, articulation, etc.). [1] It finds these irregularities by not by enlarging images or seeking greater visual definition (eg by using a higher frame rate)–not by bringing things into focus–but by paying attention to the parts of the video that are most indeterminate, fuzzy, and glitchy. As Hardesty explains on the MIT news site:
That technique passes successive frames of video through a battery of image filters, which are used to measure fluctuations, such as the changing color values at boundaries, at several different orientations — say, horizontal, vertical, and diagonal — and several different scales…Slight distortions of the edges of objects in conventional video, though invisible to the naked eye, contain information about the objects’ high-frequency vibration. And that information is enough to yield a murky but potentially useful audio signal.
So, as I understand it, the technique finds a lot of different ways to process the visual noise in the video images, and from this database of visual noise it pulls out the profile of vibrations that would generate the most probable, “common sense” auditory signal. The algorithm produces lots and lots of visual noise, because the more visual data it can collect, the more accurate a rendition of the audio signal it can produce.
If we traditionally understand listening as eliminating noise that distracts us from the signal (i.e., as focusing), this practice re-imagines listening as multiplying (visual) noise to find the (audio) signal hidden in it. Instead of tuning noise out, we amplify it so that the hidden ‘harmonics’ emerge from all the irrational noise. Listening means extracting signal from a database. Our ears alone are incapable of processing all that noise–which isn’t even auditory noise in the first place. Listening isn’t something our ears do–it’s something algorithms do. Nowhere is this more evident than in the MIT video, which shows a smartphone Shazamming the “Ice Ice Baby” riff recovered from one of their experiments. The proof of their experiment isn’t whether the audience can recognize the sound they recovered from the visual mic, but whether Shazam’s bots can.
We often talk about algorithms “visualizing” data. But what does it mean to understand them as “listening” to us, as “hearing” data, making it comprehensible to our puny, limited senses?
[1] Hardesty explains: “So the researchers borrowed a technique from earlier work on algorithms that amplify minuscule variations in video, making visible previously undetectable motions: the breathing of an infant in the neonatal ward of a hospital, or the pulse in a subject’s wrist.”
Robin is on Twitter as @doctaj.
Comments 2
Eivind — August 8, 2014
This is fun as an experiment, but seems relatively useless in practice. In principle, you could use this to recover sound from a video-call even if the microphone is muted by analyzing the video-stream instead, but there's one pretty significant "but".
Normal video is shot at 25Hz to 60Hz, and that's much too low to recover the parts of the spectrum that human hearing cares about. Notice how the movie they analyzed had been deliberately shot with a high-speed video-camera.
You can't detect frequencies higher than half your sampling-frequency, thus you can't detect sound with frequencies higher than 12Hz to 30Hz from normal video even in principle. (in practice the limits may be even lower)
You could use a telescope to high-speed-film an object far away, and recover sound from it, I suppose that might have use in certain spy-like scenarios.
Atomic Geography — August 10, 2014
Robin, enjoyed this.
Speaking of New Materialsts, Tim Morton's take on this includes:
My take would be this: Human listening also relies on accepting high noise to signal ratios. The brain using a heuristic approach transduces the sound into listening. The machine approach mimics this using the algorithm to transduce the visual into sound allowing human listening to occur in a transduced space.