

For a little over a decade, those researchers and visionaries originally involved in establishing the infrastructure for the World Wide Web have set their sights higher. While hyperlinking Web pages has been pivotal to creating a Web of documents, the more recent goals to establish a Semantic Web involve hyperlinking data, or individual elements within a Web page. In attaching unique identifiers (in the form of Uniform Resource Identifiers or URIs) and metadata to data points (rather than to just the documents where those data points appear) machines are able to interpret, not just what the browser should display, but also what the page is about. The hope is that, in providing machines with the capacity to interpret what data is about, it will be possible to drastically improve Web search and to allow researchers to perform automated reasoning on the massive amounts of data contributed to the Web. There are numerous examples where this infrastructure is already having impact (albeit largely behind-the-scenes). For instance, the New York Times has already “semantified” all of its data and created a Semantic API where researchers can query its database. Facebook’s Graph API, which employs Semantic Web infrastructure to structure user profile data, has been the foundation for several studies attempting to make sense of human behavior and interactions through the platform’s “big data.”
Inherent in the project of structuring meaning are philosophical questions about sameness and difference. How do we define and formalize identity – when one thing is exactly the same as the other? Semantic Web engineers are well-attuned to these questions; in fact, many have degrees in Philosophy. Yet, questions about sameness are difference are not just philosophical; they are also deeply political. There are social repercussions to formally marking two things as the same or two things as different. We need to be attuned to how the digital infrastructure built for the Semantic Web reflects and projects political commitments – how it shapes a politics of representation. This has serious implications for how identity can be organized, and how we (and machines) understand what the world is about as we access Web knowledge bases for information.
It is notable that establishing the infrastructure needed to meet the vision of a Semantic Web involves engineering a shared language between a content creator and a machine. What happens when language is literally engineered – when digital infrastructure deliberately structures the meaning of content on the Web?
There are several layers to the infrastructure of the Semantic Web; the most important layers are arguably schemas, semantics, and ontologies. ” Schemas provide a range of properties for describing data. For instance, a schema may provide properties such as ‘restaurant telephone number’, ‘event start date’, or ‘gender’, which can be referenced to describe a piece of data. Semantics establish the structure for how these properties and their values can be attached to data points. Semantic data is most commonly structured in “triples” of subject, predicate, object; the data point (subject) is linked to a schema property (predicate), and a value is attached to this property (object).
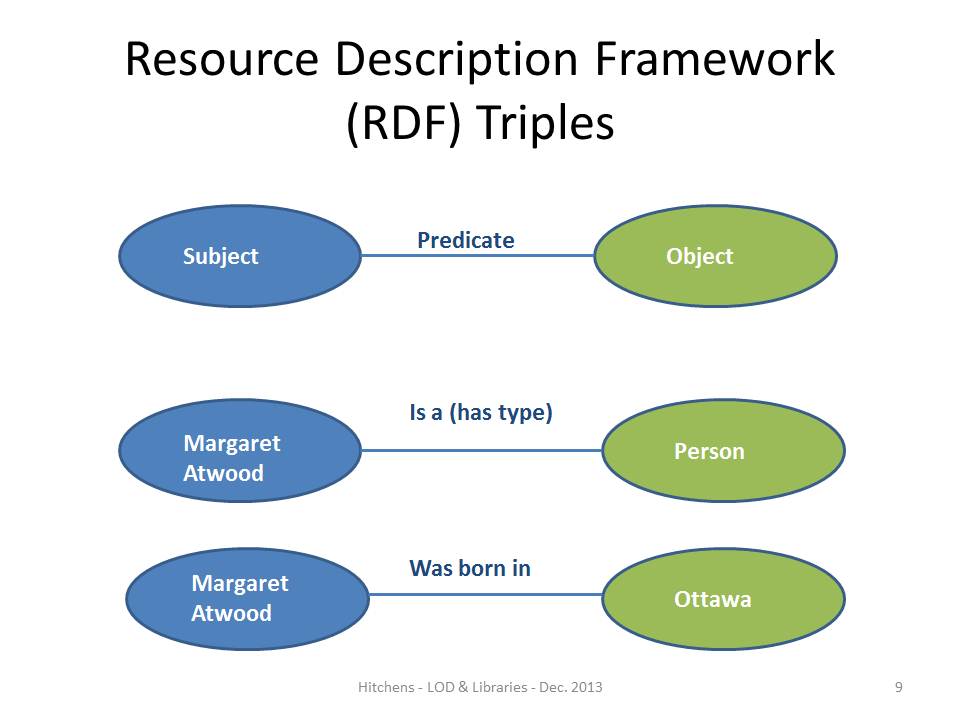
Finally, ontologies formalize how researchers mark the relationships, hierarchies, and differences between pieces of data; they offer a formal way for representing knowledge. For example, an ontology may be applied to show that Miley Cyrus is a child of Billy Rae Cyrus, or a carnivore is a subcategory of an animal. Schemas, semantics, and ontologies all become machine-readable through different coding languages and standards.
As you can imagine, building these languages and establishing these standards is quite a contentious endeavor; it involves delineating the boundaries of meaning around just about anything in the world. Tedious discussions arise as Web engineers engaged in establishing this infrastructure, in collaboration with the World Wide Web Consortium (W3C), attempt to formalize the way data should be described and ontologically represented.
Consider, for instance, “OWL:sameas”, a property in OWL (an ontology coding language) that was established to codify when two pieces of data on the Web (with two different URIs) refer to the same thing, or have the same identity. The W3C documentation outlining this property offers the following example, showing how OWL:sameas would describe a reference to William Jefferson Clinton to be the same as a reference to Bill Clinton:
<rdf:Description rdf:about=”#William_Jefferson_Clinton”>
<owl:sameAs rdf:resource=”#BillClinton”/>
</rdf:Description>
As more and more webmasters take advantage of Semantic Web infrastructure to describe their data, many Web researchers and engineers have lamented how OWL:sameas is being used and (ab)used. What happens when ‘morning star’ and ‘evening star’ are both described as being the “same as” ‘Venus’? Should the automated reasoners that attempt to make inferences from this data then assume that they are the “same as” each other? Is the time of day that Venus is seen (or “sensed” in the words of Gottlub Frege, a logician and philosopher inspiring much work in Web ontologies) a difference that makes a difference? 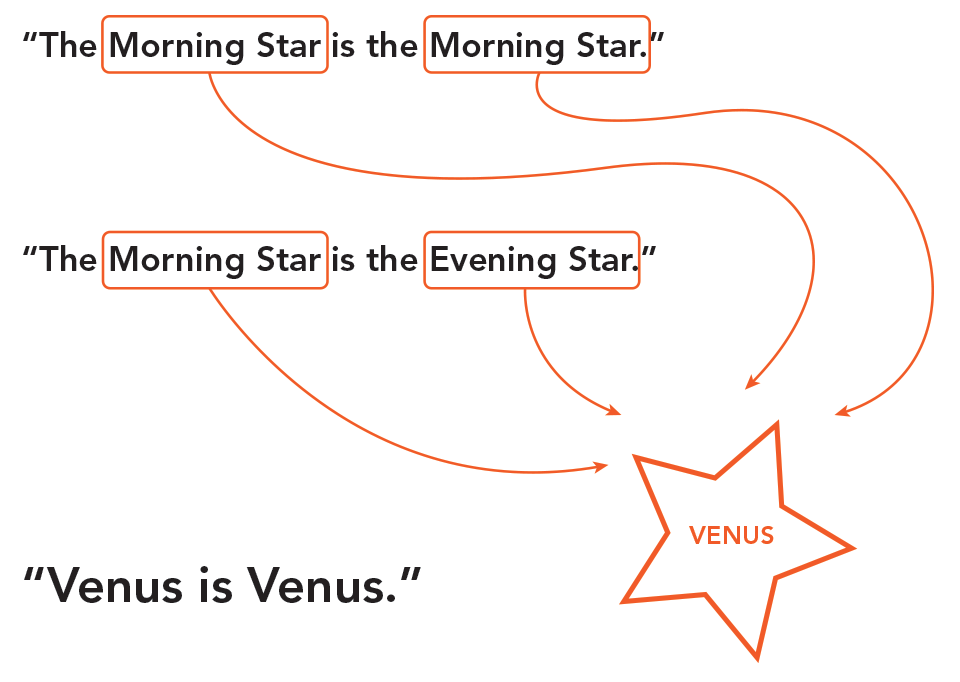 Notably, formalized logic breaks down when OWL:sameas is applied more loosely; automated reasoners produce tangled results. The stickiness of difference keeps getting in the way of clean ontological depictions of the world.
Notably, formalized logic breaks down when OWL:sameas is applied more loosely; automated reasoners produce tangled results. The stickiness of difference keeps getting in the way of clean ontological depictions of the world.
The controversial politics of representation becomes apparent as soon as OWL:sameas is applied to contested data points. Take, for example, DBpedia, a crowd-sourced project aiming to semantify data that has been contributed to Wikipedia. As of July 2015, DBpedia still has no entry for Caitlyn Jenner. But it does have an entry for Bruce Jenner. Scroll through the metadata at this URI to the OWL:sameas property, and you will find several URIs – all of which link to Web pages on Caitlyn Jenner. Other examples illustrate international naming politics. DBpedia has no entry for Myanmar, but it does have an entry for Burma. Scroll to the OWL:sameas property, and you will find that the US-based and UK-based URIs marked as being the “same as” this entry all refer to Burma, while those based elsewhere in the world refer to Myanmar – the name change the US and UK refused to recognize due to the reported human rights abuses that led to 1989 regime change.
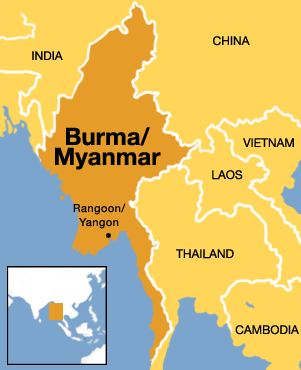 Should automated reasoners assume that a reference to Bruce Jenner is the “same as” a reference to Caitlyn Jenner, or that a reference to Burma is the “same as” a reference to Myanmar – that the two have the same “identity”? And more importantly, who gets to decide? What happens when this sameness organizes how we see data on the Web? Or when it becomes the basis of research conducted on the Web?
Should automated reasoners assume that a reference to Bruce Jenner is the “same as” a reference to Caitlyn Jenner, or that a reference to Burma is the “same as” a reference to Myanmar – that the two have the same “identity”? And more importantly, who gets to decide? What happens when this sameness organizes how we see data on the Web? Or when it becomes the basis of research conducted on the Web?
Attempts to iron out these differences, or even to nail down when and how differences make a difference, discount the importance of permitting difference to remain sticky – of allowing data to sit comfortably and uncomfortably in a conflicting ontological space of sameness and difference. In this sense, there are not just technical and philosophical difficulties to semantifying the Web; there are also political difficulties – considerations that are often ignored as Web researchers attempt to engineer vocabularies and ontologies that capture a consistent depiction of the world. This can be thought of in terms of what postcolonial and feminist theorist Gayatri Chakravorty Spivak refers to as “worlding the world.” “Worlding” refers to the way colonizers inscribe new worlds – worlds they assume were previously uninscribed. It is with this “worlding” that certain forms of meaning become salient – that the “Third World” comes to be recognized as the “Third World” and that the countries that constitute it are homogenized to sameness. We need heightened awareness of how the worlding of the Web – the engineering of semantic infrastructure – shapes what we know and can know – what can be made meaningful in a world full of sticky differences.
Lindsay Poirier is a PhD Student in Science and Technology Studies at Rensselaer Polytechnic Institute. She occasionally Tweets at @lindsaypoirier. http://lindsaypoirier.com/