

In preparation for the 2012 Quantified Self Conference on 15 and 16 September (#QS2012), I’m spending a couple weeks writing about the “self knowledge through numbers” group Quantified Self. Last week, I focused on self-quantification in relation to my masters work on what I’ve termed biomedicalization 2.0; this week, I focus on my upcoming dissertation project, which will look specifically at emotional self-quantification (or “mood tracking”).
What is mood tracking?
I became aware of mood tracking—in the self-quantification context—while I was at the first Quantified Self Conference, which took place in Silicon Valley in May of 2011. I attended some of the “lunchtime ignite talks,” and happened to catch Sarah Gray presenting on MercuryApp. Gray initially created MercuryApp (which tracks emotions for the purpose of decision-making) for herself, while she was in a long-distance relationship. She thought the relationship was great, but she and her partner were having difficulty figuring out which one of them should move. Gray created the app, used it to track her feelings about her relationship for two months, and then took her first look at the data she’d accumulated. The results surprised her: she wasn’t nearly as happy in her relationship as she thought she was. Instead of moving, or helping her partner to move, Gray broke off the relationship because of what she saw in her mood tracking data. “One sad panda you can write off,” she said in her presentation, “but many sad pandas?”

Here’s the disclaimer paragraph: mood tracking is, of course, not new. Psychologists, psychiatrists, and other mental health professionals have asked their patients to mood track as part of treatment for some time (though generally in ways that seem much more medicalized and much less user-friendly [pdf] than a touchscreen mobile app full of smiling and frowning pandas), and individuals have tracked their emotions independently (in both direct and indirect ways) through practices like journaling and diary-keeping since well before Freud. I should also note that a self-tracking tool is not automatically a tool for self-directed self-quantification just because it’s “an app”; present-day self-tracking apps map onto a continuum from medicalization to biomedicalization to biomedicalization 2.0, and mood tracking apps are no exception. A mood tracking app may be designed to collect data at a healthcare provider’s behest (medicalization), to collect data about which you’re then encouraged to ‘talk to your doctor’ (biomedicalization), or to collect data for which you yourself will be the primary sense-maker (biomedicalization 2.0).
So what do I find so interesting about mood tracking that I’m planning to do an entire dissertation about it? Below, I’ve sketched out preliminary versions of my three primary research questions; comments and questions are encouraged!
1.) What kinds of knowledges are produced through self-quantification, and through emotional self-quantification specifically? What ways of knowing—about ourselves and about the world—are opened up, and which are foreclosed? People are meaning-making creatures; we make sense of our worlds, our lives, and ourselves by creating narratives based on the information (broadly defined) available to us. What kinds of stories are easier to craft from which kinds of quantified data, and which kinds are more difficult? What kinds of frames or settings are implicitly encouraged when we use specific self-quantification tools, or when we self-quantify at all? What can we learn from self-quantification that would be much harder, if not impossible, to learn in other ways? What might self-quantification render much harder, if not impossible, to learn? What are the larger social and political consequences of embracing self-quantified ways of knowing?
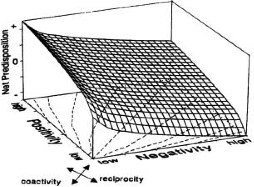
As Gary Wolf (@agaricus) illustrates, mood tracking is a lot more complicated than it might seem on the surface; it doesn’t just boil down “too many sad pandas = leave your partner.” The conclusions we might draw from mood tracking are influenced by what kind of data we gather, how we gather our data, and what frameworks we use to determine what counts as data, as well as by the questions we ask (and how we ask them, and for whom we ask them) when we sit down to make sense of that data. Furthermore, as Arlie Hochschild argues, emotions are social even when we experience them privately. How we interpret our feelings, how we feel about our feelings, and which feelings we think we’re supposed to feel in any given moment or context are all profoundly influenced both by identity and by culture; similarly, our feelings serve as important tokens of exchange in our relationships with others. Which aspects of the often-overlooked sociality of emotions are captured by different mood tracking practices? How does this affect what we learn from mood tracking?
2.) How does self-quantification compare to other forms of self-documentation, both public and private or digital and analogue? Around Cyborgology, we pay a lot of attention to self-documentation in the public and digital sense (for instance, what people chose to ‘reveal and conceal’ about themselves, and to whom, on social networking sites). Others have studied self-documentation in the primarily private and analogue sense (for instance, diary-keeping and journaling). Emotional self-quantification with mood tracking apps straddles both these loose categorical binaries: the data people generate about themselves is shaped by the affordances of different digital interfaces (as is, say, your self-documentation on Facebook), but that data is generally not meant for public consumption (eg, you might think about someday putting together a presentation on your mood tracking project for a Quantified Self meetup, but there’s a good chance you’re the only person who will ever see all of your raw data).

Of course, not all mood tracking is private, but that doesn’t make it public either. The most recent version of Mood Panda (yes, there’s more than one app in which you can be a ‘sad panda’) integrated a social sharing aspect and found that, while a number of people were eager to share their mood tracking with others, they were not particularly eager to share their mood tracking with people who knew them in any other context: only 35% of Mood Panda users used Facebook integration features, and a mere 2% use Twitter integration to cross-post there. This is interesting to me because it highlights the fact that “private” doesn’t always mean “alone” or “self-only,” just as “public” doesn’t always mean “visible” or “readily identifiable” (see also: the practice of keeping alternate social media accounts that are not access-restricted, but which are also not connected to a one’s main account or to any of one’s friends’ accounts).
3.) What does the growing popularity of emotional self-quantification tell us about the current historical moment? (Why quantification, and why now?) Emotions have confounded human beings since human beings have had emotions, but human beings have not always tried to make sense of emotions through numbers. Though emotional self-quantifiers are still in the minority (as a percentage of the overall human population), interest in emotional self-quantification is growing; we could also look at the number of different mood tracking apps available and ask why at least some people expect the interest in mood tracking to grow (else why have a start-up that makes products for mood tracking?). Alexandra Carmichael (@acarmichael) complied a list of more than 20 mood-related self-tracking tools, and that was just in 2010. At least 10 different presentations [pdf] discussed mood or emotion tracking at the 2011 Quantified Self Conference; as one attendee quipped, “This year’s cow bell = mood apps at #qs2011… every other poster/app is a mood tracker.” (Check back next week for my report on mood tracking at #QS2012.)

The easy answer here is to throw out something about ‘big data’: computers made big data possible, personal computers made personal digital data possible, and now in the era of Really Big Data (a ‘data deluge’, in fact), ‘personal profiles’, ‘ubiquitous computing’, and ‘a gene for’ just about everything, of course we’re drawn to turn a quantified gaze inward in order to make sense of ourselves in the world (or as the world?). I don’t think it’s that simple, however; I think there’s a lot more going on both with self-quantification generally and with mood tracking specifically, and that the whole picture is probably a lot more complicated, nuanced, and messy. And hopefully I’m right about this, or I’m in for a very boring dissertation! (I’m not concerned.)
Whitney Erin Boesel (@phenatypical) will be co-leading a breakout session on academic research and self-quantification at #QS2012.
Bust and bits image from http://thereisnowetware.wordpress.com/2011/06/06/critiquing-the-quantified-self/
Sarah Gray at #QS2011 photo by visually_speaking from http://www.flickr.com/photos/67339053@N00/5770771818/
Emotion graph from http://quantifiedself.com/2009/02/measuring-mood-current-resea/
Sad panda from http://www.pitt.edu/~jck49/SPASMainPage.html
Data vision image from http://www.1to1media.com/weblog/2012/06/big_datas_challenges_and_oppor.html
Comments 6
No One Tells Stories Alone » Cyborgology — September 15, 2012
[...] as Whitney Erin Boesel described in her post yesterday, we construct deeper forms of meaning and self-knowledge through technology as part of our [...]
Meaning-Making Through Numbers: Emotional Self-Quantification | Flash Politics & Society News | Scoop.it — September 16, 2012
[...] Can we create quantitative data that will help us make sense of our emotions? [...]
Meaning-Making Through Numbers: Emotional Self-Quantification » Cyborgology | The Sociology of the Quantified Self | Scoop.it — September 29, 2012
[...] [...]
Meaning-Making Through Numbers: Emotional Self-Quantification » Cyborgology | MoodPanda | Scoop.it — December 14, 2012
[...] In preparation for the 2012 Quantified Self Conference on 15 and 16 September (#QS2012), I’m spending a couple weeks writing about the “self knowledge through numbers” group Quantified Self. Last week, I focused on self-quantification in relation to my masters work on what I’ve termed biomedicalization 2.0; this week, I focus on my upcoming dissertation project, which will look specifically at emotional self-quantification (or “mood tracking”). [...]
What is the Quantified Self Now? » Cyborgology — May 23, 2013
[...] says yes, it’s a lot easier for me to explain my project (which is looking at different forms of mood tracking, primarily within the context of Quantified Self). But sometimes asking this return question makes [...]
How Your Mood Affects the Self-Quantified Revolution | SiliconANGLE — October 1, 2013
[...] app was created by Sarah Gray for her own purposes while she was in a long-distance relationship. Though the [...]