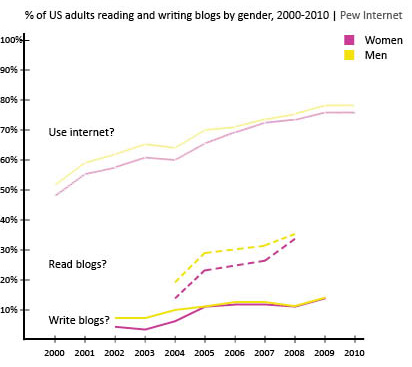
What works
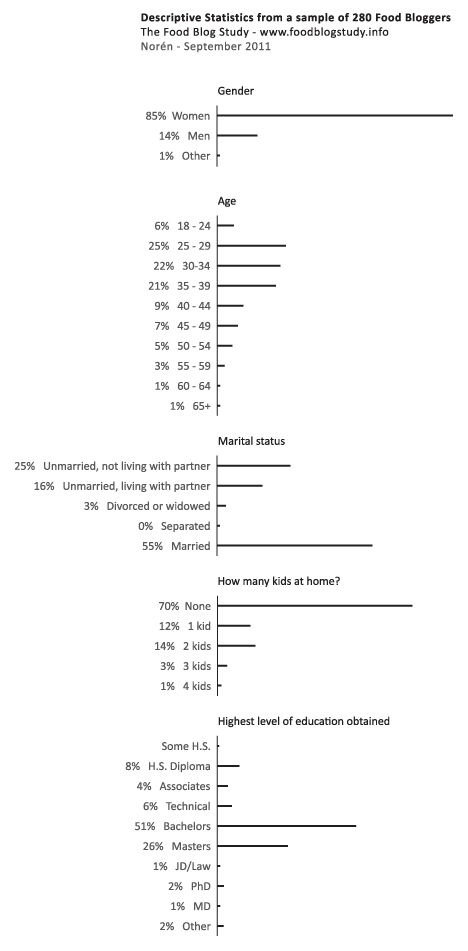
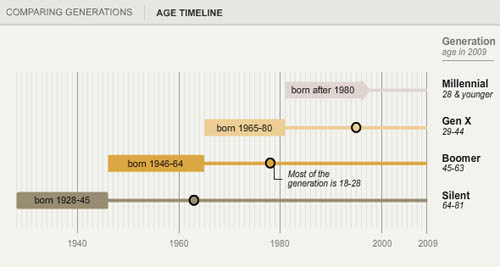
Pew Research has created a tidy series of interactive graphics to describe the demographic characteristics of American generational cohorts from the the Silent Generation (born 1928 – 1945) through the Boomers (born 1946 – 1964), Generation X (1965 – 1980) [this is a disputed age range – a more recent report from Pew suggests that Gen Xers were born from 1965-1976), and the Millennial Generation (born 1981+ [now defined as being born between 1977 and 1992]). The interactive graphics frame the data well. They offer the timeline above as contextual background and a graphic way to offer an impressionistic framework for understanding generational change.
Then users can flip back and forth between comparing each generation to another along a range of variables – labor force participation, education, household income, marital status – while they were in the 18-29 year old age group OR by looking at where each generation is now. The ability to interact makes the presentation extremely illustrative and pedagogically meaningful. It is much easier to understand patterns that are changing over time versus patterns that are life course specific.
Marital status

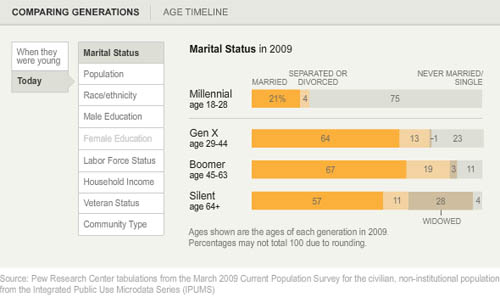
For instance, marital trends have been hard to talk about because the age at first marriage moves up over time, so it’s hard to figure out at what age we can expect that people will have gotten married if they are ever going to do so (I tried looking at marriage here).
What I like about the Pew Research graphics is that they show us not only what the generations looked like when they were between 18 and 29 years old (above) but also what they look like now (below). Not only does it become obvious how many millennials are choosing to remain unmarried (either until they are quite a bit older or forever – hard to say because the oldest millennials are still in their 30s), but it also becomes clear that in addition to divorce, widowhood is a major contributor to the end of marriage. Keep that in mind: somewhere around half of all marriages end in divorce so that means the other half ends in death. I would guess that a vanishingly small number of couples die simultaneously which means there are quite a few single older folks who did not choose to be single (of course, even if they didn’t choose to outlive their spouses, they may prefer widowhood to other alternatives, especially if their spouse had a long illness).
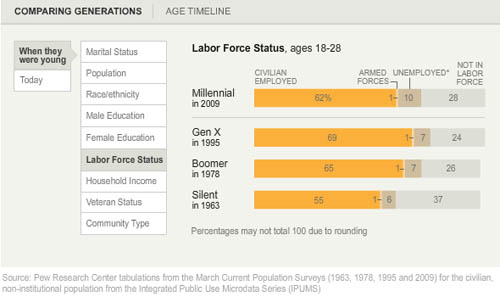
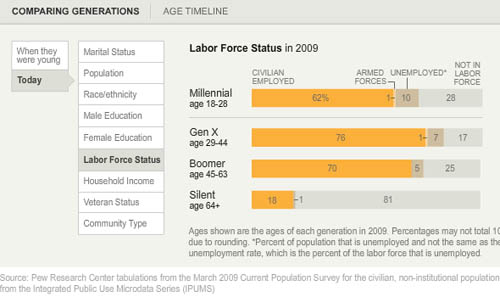
Labor force participation
Here’s another set of “when they were young” vs. “where they are now” comparisons, this time on labor force participation. It appears that the recession has walloped the youngest, least experienced workers the hardest. They have the highest unemployment rate AND the highest rate of educational attainment (and school loan debt), which leaves them much worse off as they start out than their parents were in the Boomer Generation. Even if their parents were in Generation X, they were still better off than today’s 20-something Millennials.
What needs work – Are generations meaningful?
My first minor complaint is that the graphic does not make clear *exactly* what “when they were young” means. If we look at the first graphic in the series, the timeline, it appears that “when they were young” was measured when each generation was between 18 and 29 years old. I hope that is the case. I might have had an asterisk somewhere explaining that “when they were young = when they were 18-29 years old”.
The concept of generations, in my opinion, is a head-scratcher. The idea that I had to come update this blog because the definition Pew was using to define Millennials and GenXers changed (without explanation that I could find) adds to my initial skepticism about the analytical purchase of generational categories. What is the analytical purchase of looking at generations – strictly birth-year delimited groups that supposedly share a greater internal coherence than other affinal or ascribed statuses we might imagine? If we believe that social, technological, and most all kinds of change happen over time, of course there are going to be measurable differences between one generation and the next. I imagine, though I have never seen the comparison, that if social scientists split people into 10- or 20-year pools based on their birth years they would end up with the same sorts of results. So why not think of generations as even units? And is it clear that the meaningful changes are happening in 20-year cycles? Or would 10-year age cohorts also work?
The real trickiness comes in when we think about individuals. Say someone is like myself, born in a year on the border between one generation and the next. Am I going to be just as much like a person born firmly in the middle of my cohort as a person on the far end of it? Or will people like me have about as much in common with the people about 8 years above and below us, but less in common with the people 15 years older than us who are considered to be in the same generation, and thus to have many similar tendencies/life chances/characteristics?
A better way to measure the cohort effect would seem to be to consider each individual’s age distance from each other individual in the sample – the closer we are in age, the more similar we could be expected to be with respect to things like labor force participation and educational attainment. Large structural realities like recessions are going to hit us all when we have roughly similar amounts of work force experience, impacting us similarly (though someone 10 years older and still officially in the same generation will probably fare much better). Since it is computationally possible to run models that can take the actual age distances of individuals in the same into account, I don’t understand the analytical purchase of the concept of generations.
The take-away: great graphics, bad premise.
References
Taylor, Paul and Keeter, Scott, eds. (24 February 2011) The Millenials. Confident. Connected. Open to Change. [Full Report] [See also: Executive Summary and Interactive Infographic] Washington, DC: Pew Research Center.